
У спільноті Python‑розробників давно назрів запит на приклади не «іграшкових» скриптів, а повноцінних систем, які можна запускати в продакшні. Канал Tech With Tim показує саме таку архітектуру: великий, безперервно працюючий сервіс для порівняння цін на Amazon у різних країнах, написаний повністю на Python. Це не окремий скрейпер, а цілісна система з UI, API, оркестрацією подій, логуванням, історичними даними та AI‑шаром для подальших запитів.
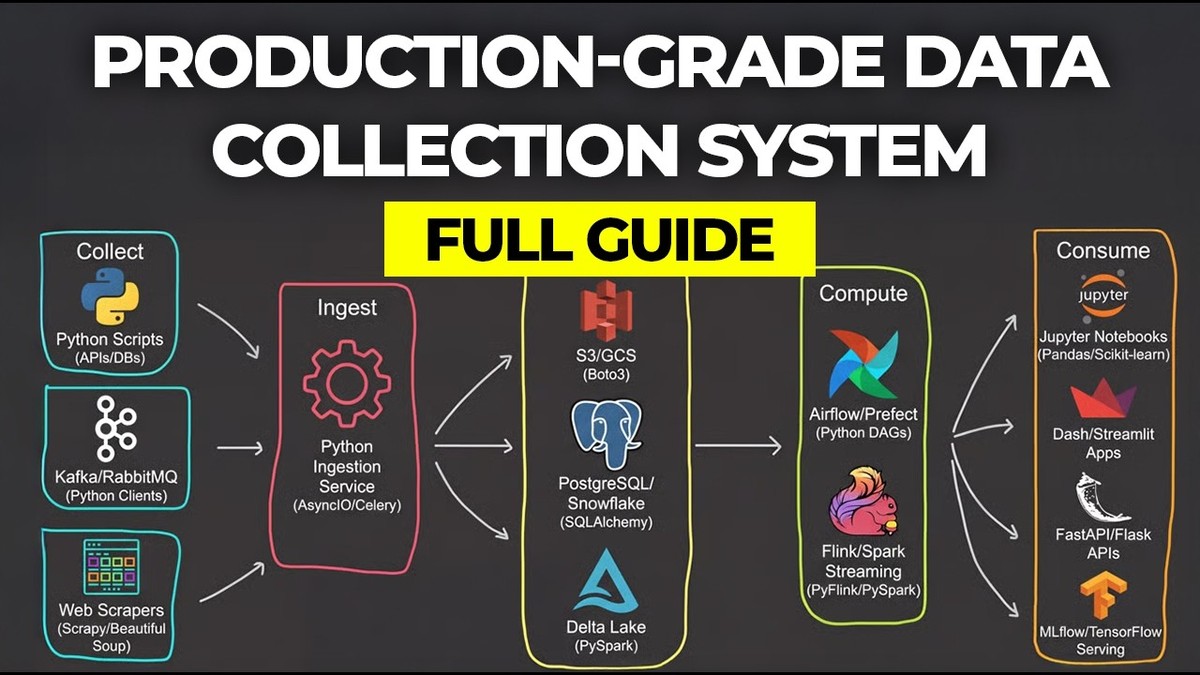
Йдеться про інструмент, який за ASIN (ідентифікатор товару на Amazon) збирає дані з кількох регіональних доменів — від США та Канади до Франції, Іспанії, Австралії, Японії й ОАЕ — і дозволяє аналізувати різницю цін у реальному часі. Під капотом — Streamlit як фронтенд, FastAPI як бекенд‑API, подієво‑орієнтований бекенд на Ingest, окремий шар скрейпінгу, сховище даних і контейнеризація через Docker. Увесь код відкритий на GitHub.
Від «одноразового скрипта» до системної архітектури
Будь‑хто, хто виходив за межі «швидкого скрипта на requests + BeautifulSoup», знайомий із типовим сценарієм: перша версія працює, потім починаються блокування, різні країни повертають різні сторінки, сесії «падають», дані стають непослідовними, і довіра до результатів зникає. У цей момент задача перестає бути суто «про код» і перетворюється на задачу про великі розподілені системи.
У випадку з Amazon це особливо помітно. Один і той самий товар може бути присутнім на кількох локальних сайтах — наприклад, у Франції, Іспанії, ОАЕ, Канаді, США — з різними цінами, валютами, іноді й різними варіантами упаковки. Якщо бізнес хоче бачити цю картину в динаміці, а не разово, потрібна система, яка:
- працює безперервно, а не запускається вручну раз на тиждень;
- масштабується по регіонах і по кількості товарів;
- зберігає історичні дані, а не просто «останній знімок»;
- залишається придатною до запитів згодом, у тому числі через AI‑шар, де користувач ставить питання природною мовою.
Саме під ці вимоги і спроєктовано архітектуру Amazon Price Scraper на Python. На верхньому рівні вона складається з кількох чітко розділених компонентів: інтерфейс користувача, API‑шар, подієво‑орієнтований бекенд, шар скрейпінгу, сховище даних і AI‑шар для запитів. Кожен із них реалізований на Python, але виконує свою роль у загальній системі.
Streamlit як фронтенд: простий UI для складної системи
Зовні система виглядає доволі скромно, але саме так і має виглядати хороший технічний інструмент: мінімум зайвого, максимум функціональності. Фронтенд побудований на Streamlit — Python‑фреймворку, який дозволяє швидко створювати інтерактивні веб‑інтерфейси без окремого JavaScript‑стека.
Користувач бачить кілька ключових можливостей.
По‑перше, поле для введення ASIN. Це унікальний ідентифікатор товару на Amazon, який можна просто скопіювати з URL сторінки товару. Система працює саме з ним, а не з текстовим пошуком, що дозволяє однозначно ідентифікувати продукт.
По‑друге, вибір цільових країн. Інтерфейс дозволяє відзначити, з яких регіональних доменів Amazon потрібно зібрати дані. У демонстрації використовуються США, Канада, Велика Британія, Франція, Іспанія, Австралія, Японія та ОАЕ. Це не жорстко зашитий список, а радше приклад того, як система може працювати з різними ринками.
По‑третє, запуск скрейпінгу. Після введення ASIN і вибору країн користувач натискає кнопку на кшталт «Scrape product», і далі в гру вступають бекенд‑компоненти. Streamlit у цьому місці не виконує жодної «важкої» роботи — він лише формує запит до API‑шару.
По‑четверте, перегляд результатів. Інтерфейс показує таблицю з товарами, де видно, з яких країн вдалося зібрати дані, які ціни повернув кожен регіональний сайт, у якій валюті, які додаткові атрибути вдалося витягнути. У прикладі демонструються товари на кшталт Scrub Daddy, Kleenex, iPad, бритви чи дезодоранту Axe, для яких система знаходить різні ціни в різних країнах.
Окремий вкладений розділ інтерфейсу присвячений порівнянню цін. Там можна сфокусуватися на товарах, які мають кілька записів із різних країн, і побачити різницю у вигляді графіків та агрегованої інформації. Це вже не просто «таблиця скрейпінгу», а інструмент для аналізу.
Нарешті, є вкладка з AI‑чатом. Вона дозволяє ставити запитання природною мовою — наприклад, «What is the price of an iPad?» — і отримувати відповідь, сформовану на основі даних у базі. Користувачеві не потрібно знати структуру таблиць чи писати SQL‑запити: система сама звертається до сховища, знаходить релевантні записи й повертає відповідь у зручному вигляді.
Ключовий момент: Streamlit тут — лише тонкий клієнт. Уся логіка — від запуску скрейпінгу до AI‑відповідей — винесена в бекенд, з яким Streamlit спілкується через HTTP‑запити.
FastAPI як API‑шар: міст між UI та бекенд‑сервісами
Щоб відв’язати інтерфейс від бізнес‑логіки, використовується FastAPI — сучасний Python‑фреймворк для побудови високопродуктивних REST‑API. Він виконує роль центрального API‑шару, через який усі зовнішні клієнти взаємодіють із системою.
У цьому підході є кілька важливих наслідків.
По‑перше, Streamlit не прив’язаний жорстко до конкретної реалізації. Якщо завтра знадобиться мобільний додаток або інший веб‑інтерфейс, вони зможуть використовувати той самий FastAPI‑бекенд. Це робить систему гнучкішою й придатною до розширення.
По‑друге, FastAPI стає єдиною точкою входу для всіх операцій: запуску скрейпінгу, запитів до історичних даних, виклику AI‑шару. Це спрощує авторизацію, логування, обмеження швидкості запитів і будь‑які інші крос‑сервісні політики.
По‑третє, API‑шар чітко розділяє синхронні та асинхронні операції. Наприклад, запит на скрейпінг товару не обов’язково повинен чекати завершення всіх HTTP‑запитів до Amazon. FastAPI може прийняти запит, передати його в подієво‑орієнтований бекенд, повернути користувачеві підтвердження, а потім дозволити UI періодично опитувати статус або отримувати оновлення.
У результаті FastAPI виступає не просто «тонким маршрутизатором», а повноцінним шаром, який інкапсулює бізнес‑логіку, пов’язану з життєвим циклом запитів, і водночас залишається достатньо легким, щоб масштабуватися горизонтально.
Подієво‑орієнтований бекенд на Ingest: серце оркестрації
Справжня складність починається там, де система має працювати безперервно, обробляти помилки, повторювати спроби, логувати кожен крок і дозволяти розробнику «зазирнути всередину» будь‑якого запуску. Для цього в архітектурі використовується Ingest — інструмент, який поєднує оркестрацію, логування, моніторинг і проксіювання запитів.
Ingest розгортається як окремий сервіс і виступає проміжною ланкою між зовнішніми запитами та внутрішніми функціями. Він дозволяє огорнути ключові операції в так звані «моніторені функції», кожен виклик яких фіксується як окремий «run» із повною історією подій.
У системі визначено дві базові оркестровані функції.
Перша — «querying products», тобто запит продуктів. Вона відповідає за отримання вже наявних у базі даних записів, агрегацію інформації, підготовку відповідей для UI або AI‑шару. Це шар, який працює з історичними даними, не запускаючи новий скрейпінг без потреби.
Друга — «scraping products», тобто скрейпінг продуктів. Саме вона ініціює HTTP‑запити до Amazon через проксі‑мережу, обробляє HTML, зберігає результати, ініціює подальші кроки на кшталт векторизації даних для AI‑запитів. Ця функція має бути стійкою до помилок: якщо товар не знайдено, сторінка повернулася в іншому форматі, стався тайм‑аут чи тимчасове блокування, система не повинна «падати» — вона має коректно зафіксувати помилку, за потреби повторити спробу й повернути осмислений результат.
Панель Ingest дозволяє в реальному часі спостерігати за цими процесами. Кожен запуск скрейпінгу відображається як окремий запис із часовими мітками, статусами, вхідними параметрами (ASIN, країна), проміжними результатами (категорії товару, атрибути, час виконання окремих кроків) і фінальним статусом. Якщо щось пішло не так, можна зайти в конкретний run, побачити, на якому кроці сталася помилка, і перезапустити його або скасувати.
Це критично для продакшн‑системи, яка має працювати «на потоці». Без такого рівня прозорості розробник швидко опиняється в ситуації, коли «щось десь не працює», але зрозуміти, що саме, майже неможливо. Ingest знімає цю проблему, роблячи кожен крок скрейпінгу й обробки даних відстежуваним.
Важливо й те, що Ingest виступає проксі‑шаром для FastAPI. Зовнішні запити можуть надходити через Ingest, який, у свою чергу, викликає відповідні ендпоїнти FastAPI, логуючи всі події по дорозі. Це створює єдину картину того, що відбувається в системі — від кліка користувача в UI до запису в базі даних.
Безперервність, масштабування та історичні дані
Архітектура спроєктована так, щоб система могла працювати безперервно й масштабуватися як по кількості товарів, так і по регіонах. Це означає, що скрейпінг не обмежується одноразовим запуском для одного ASIN. Система здатна обробляти «ефективно необмежену» кількість продуктів, запускаючи паралельні завдання, розподіляючи навантаження між контейнерами й регіонами.
Ключовий аспект — зберігання історичних даних. Замість того щоб перезаписувати інформацію про товар при кожному новому скрейпінгу, система зберігає часові зрізи. Це дозволяє аналізувати динаміку цін, відстежувати, як змінюється політика ціноутворення в різних країнах, і будувати більш складні аналітичні моделі.
Ще один важливий момент — готовність до подальших AI‑запитів. Архітектура з самого початку передбачає, що дані мають бути не лише збережені, а й легко доступні для AI‑шару, який зможе відповідати на запитання природною мовою. Це впливає на те, як структуруються записи, які метадані зберігаються, як організовано індексацію.
У підсумку система не просто «збирає HTML і парсить ціну», а будує повноцінне сховище знань про товари й ціни на Amazon у різних країнах, до якого можна звертатися як через класичні запити, так і через AI‑агента.
Контейнеризація: Docker як основа продакшн‑розгортання
Щоб наблизити середовище розробки до продакшн‑умов, архітектура використовує Docker і Docker Compose. Кожен основний компонент системи запускається в окремому контейнері, що дозволяє чітко розділити відповідальність і спростити розгортання.
У типовій конфігурації в окремих контейнерах працюють:
MongoDB — документно‑орієнтована база даних, у якій зберігаються сирі дані про товари, історичні ціни, метадані про скрейпінг. Вона виступає основним сховищем структурованої інформації, до якої звертаються як UI, так і бекенд‑сервіси.
Qdrant — локальна векторна база даних, яка зберігає векторні подання (ембеддинги) інформації про товари. Вона використовується AI‑шаром для ефективного пошуку релевантних записів при запитах природною мовою. Хоча деталі AI‑агента виходять за рамки цього матеріалу, важливо, що Qdrant інтегровано в загальну архітектуру як окремий сервіс.
FastAPI — бекенд‑API, який обробляє запити від Streamlit та інших потенційних клієнтів, викликає оркестровані функції, працює з базами даних і координує бізнес‑логіку.
Ingest — оркестраційний, логувальний і моніторинговий шар, який проксіює запити до FastAPI, відстежує виконання функцій, зберігає логи й надає веб‑інтерфейс для аналізу запусків.
Streamlit — фронтенд‑інтерфейс, який користувач бачить у браузері. Він спілкується з FastAPI, відображає результати, дає змогу запускати скрейпінг і ставити AI‑запитання.
Docker Compose описує, як ці контейнери взаємодіють між собою: які порти відкриті, які мережі використовуються, які змінні середовища потрібні кожному сервісу. Це дозволяє розгорнути всю систему однією командою, отримавши середовище, максимально наближене до продакшн‑інфраструктури.
Такий підхід спрощує масштабування. Якщо, наприклад, навантаження на FastAPI зростає, можна підняти кілька його екземплярів за балансувальником. Якщо потрібно більше ресурсів для Ingest або для баз даних, їхні контейнери можна масштабувати окремо. Водночас розробник працює з єдиним docker‑композ‑файлом, не занурюючись у деталі кожного окремого сервера.
Відкритий код і можливість адаптації
Один із важливих аспектів цієї архітектури — її відкритість. Повний код проєкту опубліковано на GitHub за адресою:
https://github.com/techwithtim/AmazonPriceScraper-Python
Це означає, що розробники можуть не лише подивитися на діаграми й загальні принципи, а й вивчити конкретну реалізацію: як організовано модулі, як описано моделі даних, як налаштовано взаємодію між FastAPI та Ingest, як Streamlit формує запити, як виглядає docker‑композ‑конфігурація.
Важливо й те, що архітектура побудована повністю на Python. Це знижує поріг входу для тих, хто вже працює з цією мовою, і дозволяє адаптувати систему під власні задачі: змінити цільові сайти, додати нові країни, інтегрувати інші джерела даних, розширити AI‑шар або замінити окремі компоненти на альтернативи.
При цьому загальні принципи залишаються тими самими: чітке розділення шарів, подієво‑орієнтована оркестрація, прозоре логування, контейнеризація й орієнтація на безперервну роботу з історичними даними.
Висновок: Python‑стек, який виходить за межі «скрипта»
Архітектура Amazon Price Scraper демонструє, як знайомі Python‑інструменти — Streamlit, FastAPI, бібліотеки для скрейпінгу, бази даних — можна скласти в повноцінну продакшн‑систему. Ключова ідея полягає не в окремих технологіях, а в тому, як вони поєднані: UI, який не знає про деталі бекенду; API‑шар, який інкапсулює бізнес‑логіку; подієво‑орієнтований бекенд, що забезпечує прозору оркестрацію; сховище, готове до історичного аналізу й AI‑запитів; контейнеризація, яка робить усе це переносимим і масштабованим.
У результаті виходить система, здатна безперервно збирати дані про ціни на Amazon у різних країнах, зберігати їх у зручному для аналізу вигляді й надавати до них доступ як через класичний інтерфейс, так і через AI‑чат. Для бізнесів, які працюють в e‑commerce, це перетворюється на інструмент конкурентної розвідки; для розробників — на практичний приклад того, як виглядає продакшн‑рівнева архітектура на чистому Python.
Джерело
How to Design a Production-Grade System in Python — Tech With Tim