
У сучасних компаніях щосекунди відбуваються мільйони подій: кліки користувачів, зчитування сенсорів, фінансові транзакції. Канал Confluent Developer нагадує: усе це спочатку існує як безперервний потік подій, але більшість організацій майже миттєво «заморожують» його у файлах чи таблицях, втрачаючи реальний час і створюючи штучні затримки.
Дані народжуються в реальному часі
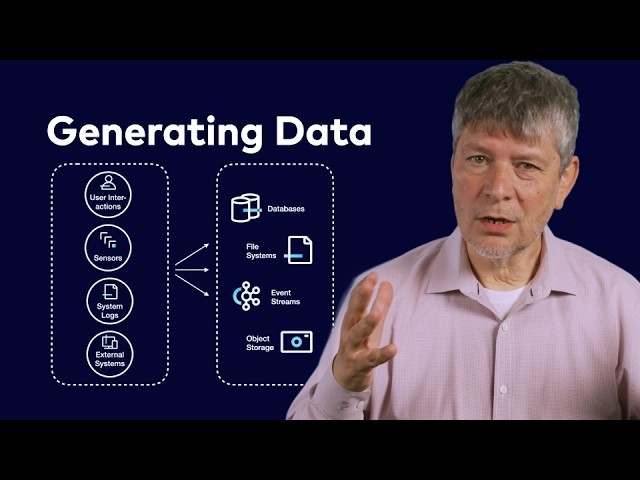
Ключова відправна точка — розуміння того, що «дані при спокої» (data at rest) з’являються не самі по собі. Вони є наслідком реальних подій, які відбуваються просто зараз:
- клік «Додати в кошик» на сайті;
- платіж у терміналі;
- показник температури з датчика;
- запис у логах застосунку.
Це і є перша фаза життєвого циклу даних: генерація з реальних бізнес-процесів та активності користувачів. Вона завжди відбувається в реальному часі.
Проблема в тому, що доступ до цих даних часто організований не як потік, а як батч: синхронізація раз на 30 секунд, раз на годину чи навіть раз на добу. Генерація — безперервна, а доступ — порційний. Так виникає штучна латентність між моментом події та моментом, коли системи можуть на неї відреагувати.
Подієво-орієнтовані системи: робота в ритмі реального світу
Відповідь на цю суперечність — подієво-орієнтована (event-driven) архітектура. Її базовий принцип: система з самого початку проєктується так, ніби дані надходять постійно й у реальному часі.
Це означає:
- система реагує на подію одразу після її появи;
- логіка обробки не прив’язана до фіксованих вікон батчів;
- потік подій — базова модель, а не похідний артефакт.
Навіть якщо зовнішні обмеження змушують отримувати дані батчами (наприклад, раз на 15 хвилин), їх можна обробляти так, ніби кожна подія прийшла окремо й «щойно». Тобто:
- батч — лише транспортний компроміс;
- семантика обробки залишається подієвою.
Перевага такого підходу в тому, що коли обмеження зникнуть (кращий зв’язок, інші протоколи, нові інтеграції), система вже готова до справжнього стрімінгу — її не потрібно перебудовувати.
Подієво-орієнтовані системи добре працюють саме тому, що вони узгоджені з природою реального світу: події не «чекають» зручного часу, вони просто трапляються.
Ви не контролюєте джерела — але контролюєте реакцію
У більшості організацій команди, що будують аналітику та стрімінгові пайплайни, не керують джерелами даних:
- продуктові команди створюють бізнес-події в застосунках;
- інфраструктурні — генерують метрики та логи;
- сторонні пристрої й сервіси мають власні графіки синхронізації.
Тому:
- неможливо диктувати, коли саме будуть згенеровані дані;
- неможливо нав’язати формат чи частоту їх передачі;
- дані «приходять, коли приходять», а не тоді, коли зручно пайплайну.
Реалістична роль дата-інженерії в такому середовищі — не змінювати джерела, а будувати системи, які:
- приймають події в будь-який момент;
- одразу запускають обробку після надходження;
- мінімізують додаткову затримку, яку створює сама організація.
Де зберігаються події і як ми втрачаємо їхній потік
Усі згенеровані події спочатку потрапляють в операційні системи — те, що часто називають operational estate:
- транзакції — в OLTP-бази;
- зчитування сенсорів — у файли або черги повідомлень;
- помилки й технічні події — у журнали логів.
Ці системи оптимізовані для швидкого запису й підтримки бізнес-операцій, а не для аналітики. Але саме тут починається будь-який дата-пайплайн.
Типова помилка організацій — одразу перетворювати цей потік на статичні файли чи таблиці, а потім обробляти їх великими батчами за розкладом. Так:
- природний стрімінг подій «ламається»;
- додаються години або дні затримки;
- втрачається можливість реагувати в реальному часі.
Альтернатива — зберігати події в системах, які зберігають їхню стрімінгову природу (наприклад, у логах подій на кшталт Apache Kafka) і будувати обробку поверх цього потоку.
Приклади: від веб-кліків до турбін
Різні джерела даних по-різному поєднують реальний час генерації та доступу.
Коли все під контролем
Є категорії даних, де генерацію й доступ можна повністю синхронізувати:
- взаємодія користувача з вебзастосунком — кліки, сабміт форм;
- логи застосунків і інфраструктури — помилки, метрики продуктивності.
У цих випадках події можна одразу відправляти в стрімінговий пайплайн і обробляти без затримки. Це «золотий стандарт»: момент створення події ≈ момент її обробки.
Коли пристрій збирає в реальному часі, але передає із затримкою
Інша ситуація — IoT та мобільні пристрої, де генерація безперервна, але передача обмежена:
- смарт-годинник щосекунди вимірює пульс, кроки, GPS, але зберігає дані локально й синхронізується лише поруч із телефоном або Wi‑Fi;
- глюкометр робить заміри кожні 30 секунд, але може тримати їх у пам’яті до восьми годин, якщо немає зв’язку з телефоном.
У цих сценаріях:
- генерація — реальний час;
- доступ — відкладений, батчами.
Ключовий принцип: як тільки батч доходить до системи, його потрібно обробити негайно, не додаючи ще одну «штучну» затримку у вигляді годинних чи добових джобів.
Коли мережа диктує ритм
Ще один приклад — вітрові турбіни, які постійно вимірюють швидкість вітру, температуру, показники продуктивності, але надсилають дані, скажімо, раз на 15 хвилин через обмеження мережі.
Оптимальна стратегія:
- приймати 15-хвилинні батчі як «знімок потоку»;
- одразу запускати обробку;
- проєктувати пайплайн так, щоб він легко перейшов до більш частих оновлень, якщо з’явиться кращий канал зв’язку.
У всіх цих прикладах спільний знаменник один: момент, коли дані стають доступними, не підконтрольний команді, що будує аналітику. Але момент, коли починається обробка після їх надходження, — підконтрольний повністю.
Головний принцип: обробляти одразу, як тільки дані з’явилися
Звідси випливає базове правило для будь-якої сучасної дата-системи:
Ви не контролюєте, коли отримаєте дані. Але ви повністю контролюєте, наскільки швидко почнете їх обробляти.
Незалежно від того, чи надходять події щосекунди, щохвилини або раз на кілька годин, пайплайн має бути готовий:
- прийняти їх у момент появи;
- запустити обробку без додаткових затримок;
- зберегти подієву модель, навіть якщо транспорт — батчевий.
Саме так вдається зберегти природну стрімінгову природу даних — від моменту їх народження до моменту, коли бізнес отримує з них користь.
Джерело
Why All Data Starts as a Stream (And How We Break It) — Confluent Developer