
У новому проєкті Tech With Tim показано не просто «черговий скрепер», а повноцінну продакшн‑архітектуру для великомасштабного збору цін з Amazon у різних країнах. Одна з найцікавіших частин цієї системи — AI‑шар поверх історичних даних, який дозволяє ставити запитання на кшталт «Яка ціна iPad?» і отримувати відповідь не з живого сайту, а з власної бази, наповненої скрепером.
Цей матеріал розбирає саме цю AI‑надбудову: як поєднуються MongoDB, Qdrant, OpenAI та LangChain, чому дані зберігаються одразу у двох різних сховищах і як це перетворює звичайний скрепер на інструмент аналітики для e‑commerce.
Від «скрипта на вихідні» до AI‑шару над історичними даними
Більшість скреперів живуть недовго: їх запускають, отримують CSV, далі все забувається. У продакшн‑системі, яку демонструє автор, підхід інший: scraped‑дані розглядаються як довгостроковий актив, до якого потрібно мати зручний доступ і через тиждень, і через пів року.
Система збирає інформацію про товари з Amazon у різних країнах, порівнює ціни для одного й того ж ASIN і зберігає результати. Користувач може через інтерфейс ввести ASIN, обрати країни (США, Канада, Велика Британія, Франція, Іспанія, Австралія, Японія, ОАЕ тощо) і отримати таблицю з цінами та додатковими атрибутами. Є окрема вкладка для візуального порівняння товарів, які присутні одразу в кількох регіонах.
Але ключова інновація — не в UI, а в тому, що над усім цим збудовано AI‑чат. Замість того, щоб писати SQL‑запити або вручну фільтрувати таблиці, користувач може просто запитати: «What is the price of an iPad?» і отримати відповідь, сформовану на основі вже зібраної бази. Це не «пошук по сайту Amazon», а запит до власного сховища scraped‑даних, яке система підтримує та оновлює.
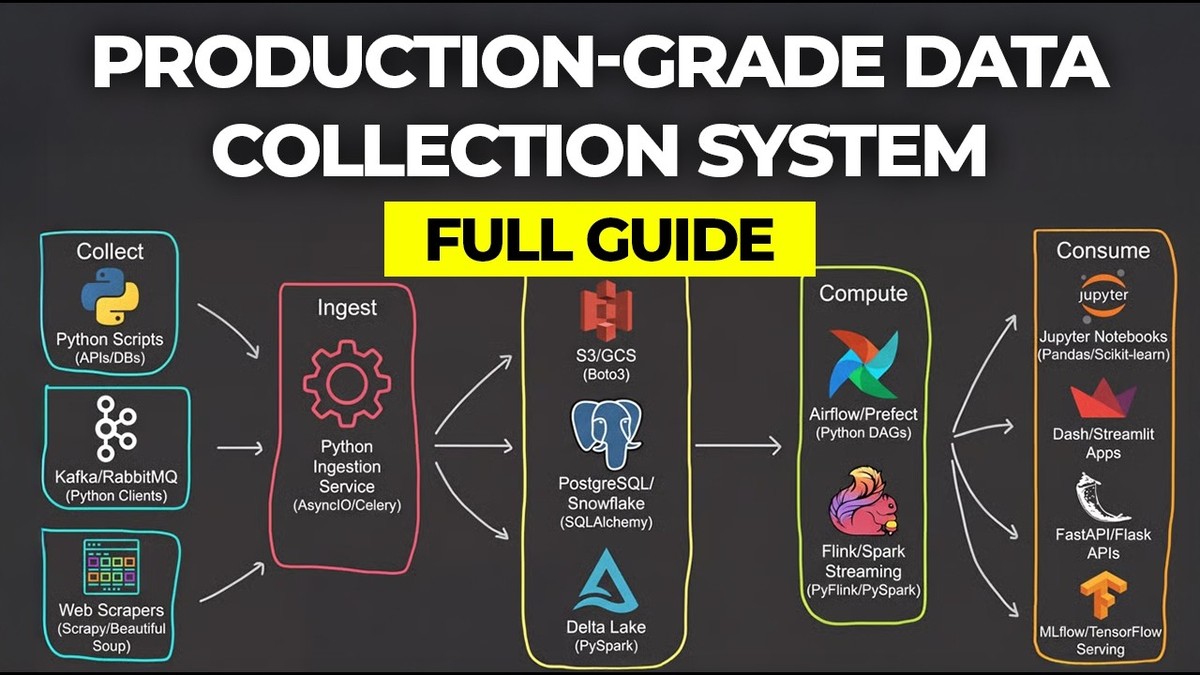
Щоб це працювало, архітектура розділяє ролі між кількома компонентами:
MongoDB — основне джерело істини для структурованих даних про товари.
Qdrant — локальна векторна база для семантичного пошуку по тим самим товарам.
OpenAI — генератор ембедингів і LLM‑модель, яка формує відповіді.
LangChain — «клей», що збирає все це в агента з інструментами.
MongoDB як джерело істини: чому класична база все ще критична
Попри модний стек з векторними базами та LLM, фундамент системи — звичайна документна база даних. Усі scraped‑дані з Amazon зберігаються в MongoDB і саме вона виступає основним джерелом істини.
Коли скрепер успішно витягує сторінку товару, він парсить HTML (через Beautiful Soup) і формує структурований запис: назва, бренд, ціна, валюта, категорії, країна, ASIN та інші атрибути. Цей запис потрапляє в MongoDB і залишається там як історичний факт. Якщо товар оновлюється або скрепер запускається повторно, система може зберігати нові «зрізи» даних, формуючи часовий ряд цін.
Такий підхід вирішує кілька задач одночасно.
По‑перше, забезпечує надійність. Навіть якщо AI‑шар тимчасово недоступний, дані залишаються в MongoDB і можуть бути використані через будь‑який інший інтерфейс — від аналітичних скриптів до BI‑інструментів.
По‑друге, гарантує відтворюваність. Відповідь AI‑агента завжди можна «приземлити» до конкретних документів у базі: які саме записи про iPad були знайдені, з яких країн, з якими цінами.
По‑третє, дозволяє будувати додаткові сервіси поверх тих самих даних. Наприклад, окремий API для партнерів, внутрішні дешборди, звіти для відділу закупівель — усе це може напряму читати з MongoDB, не торкаючись векторної бази чи LLM.
MongoDB у цій архітектурі — не «застарілий реляційний рудимент», а опорний шар, без якого AI‑надбудова не мала б стабільної основи.
Qdrant і ембединги: як перетворити базу товарів на семантичний простір
Другий ключовий компонент — Qdrant, локальна векторна база даних. Вона не дублює MongoDB, а доповнює її, зберігаючи іншу проєкцію тих самих даних.
Після того як товар збережено в MongoDB, система формує текстове представлення цього запису: назва, опис, бренд, категорії, можливо, ключові характеристики. Цей текст відправляється в OpenAI, де модель ембедингів перетворює його на числовий вектор у багатовимірному просторі. Саме ці вектори й потрапляють у Qdrant.
Таким чином, кожен товар існує у двох формах:
як структурований документ у MongoDB;
як вектор у Qdrant, що відображає його семантичний зміст.
Це відкриває можливість семантичного пошуку. Коли користувач ставить запитання природною мовою, система знову використовує OpenAI для побудови ембедингу вже для запиту. Далі цей вектор порівнюється з векторами товарів у Qdrant, і база повертає найбільш близькі за змістом позиції.
Такий підхід дозволяє знаходити товари навіть тоді, коли формулювання запиту не збігається з точними назвами в базі. Наприклад, запит «cheap Apple tablet» може привести до того самого iPad, навіть якщо в назві товару немає слова «cheap», а в базі він зберігається як «Apple iPad 10.2‑inch (9th Generation)».
Важливий момент: Qdrant у цій системі використовується як локальна векторна база. Це означає, що всі ембединги зберігаються на стороні розробника, а не в хмарному сервісі, що спрощує контроль над даними та зменшує залежність від сторонніх платформ.
OpenAI та LangChain: як зібрати агента з інструментами
Щоб перетворити MongoDB і Qdrant на єдиний інтелектуальний шар, система використовує LangChain — фреймворк для побудови LLM‑агентів. У цій архітектурі LangChain виступає як диспетчер, що дає моделі набір інструментів і навчає її, коли і як ними користуватися.
Набір інструментів агента включає три основні можливості.
По‑перше, інструмент для запитів до Qdrant. Він дозволяє за ембедингом запиту знайти релевантні товари, не вдаючись до повнотекстового пошуку чи жорстких фільтрів.
По‑друге, інструмент для доступу до MongoDB. Після того як знайдено список релевантних товарів, агент може витягнути повні документи з бази: точні ціни, валюти, країни, бренди, категорії та інші поля.
По‑третє, інструмент для виклику скрепера Amazon. Якщо в базі немає потрібних даних або вони застарілі, агент може ініціювати новий скрепінг через бекенд, який у свою чергу використовує проксі Thor Data та Beautiful Soup. Це дозволяє поєднати історичні дані з можливістю оновлення в реальному часі, хоча ключовий акцент саме на роботі з уже зібраною історією.
OpenAI у цій схемі виконує дві ролі.
Перша — генерація ембедингів для товарів і запитів, які потім потрапляють у Qdrant.
Друга — робота LLM, що стоїть в основі агента. Саме ця модель аналізує запит користувача, вирішує, які інструменти викликати, інтерпретує результати з Qdrant і MongoDB та формує фінальну відповідь природною мовою.
LangChain дозволяє описати цей процес як послідовність кроків: від семантичного пошуку до збагачення даними з MongoDB і, за потреби, запуску нового скрепінгу. Для розробника це означає, що складна багатокомпонентна логіка ховається за відносно декларативною конфігурацією агента.
Як працює запит користувача: від фрази до конкретної ціни
Щоб зрозуміти, як усі ці компоненти взаємодіють, варто розкласти типовий сценарій запиту на кроки. Наприклад, користувач у чаті вводить: «What is the price of an iPad?».
Спочатку LLM аналізує запит і розуміє, що йдеться про товар, а не про загальну інформацію чи інструкцію. Далі агент через LangChain викликає інструмент семантичного пошуку в Qdrant. Запит перетворюється на ембединг за допомогою OpenAI, і Qdrant повертає список найбільш релевантних товарів, які в базі виглядають як різні моделі iPad, зібрані з різних доменів Amazon.
Після цього агент використовує інструмент доступу до MongoDB, щоб отримати повні документи для знайдених товарів. Тут уже з’являються конкретні поля: ціна, валюта, країна, можливо, дата останнього скрепінгу.
На основі цих даних LLM формує відповідь. У демонстрації система повертає не лише одну цифру, а й перелік знайдених варіантів із деталями: з яких регіонів є дані, які ціни, які моделі. Важливо, що відповідь «заземлена» на реальні записи в базі, а не є вигадкою моделі.
Якщо ж у Qdrant або MongoDB немає жодного релевантного запису, агент може, за заданою логікою, викликати інструмент скрепера, щоб спробувати отримати свіжі дані. Але навіть без цього кроку архітектура вже дозволяє працювати з історичним масивом scraped‑інформації як з живою базою знань.
Чому історичні scraped‑дані мають жити під AI‑шаром
Ключова ідея цієї архітектури — не лише в тому, щоб «додати чат» до скрепера, а в тому, щоб зробити історичні дані повноцінним об’єктом аналітики.
Система спроєктована так, що все, що колись було зібрано скрепером, залишається доступним для запитів через AI‑агента. Це означає, що:
аналітик може повернутися до даних за минулі місяці й порівняти динаміку цін без необхідності піднімати старі CSV;
бізнес може ставити запитання природною мовою, не думаючи про структуру бази, назви полів чи формат дат;
розробник може розширювати логіку агента, додаючи нові інструменти (наприклад, агрегацію по часу чи фільтрацію за брендом), не змінюючи саму модель даних.
Такий підхід особливо цінний для e‑commerce‑компаній, які хочуть системно відстежувати конкурентні ціни в різних країнах. Замість того щоб кожного разу запускати одноразовий скрепінг і вручну аналізувати результати, вони отримують постійно оновлювану базу, до якої можна звертатися як до внутрішнього «цінового GPT».
Важливо й те, що AI‑шар не замінює класичні інструменти аналітики, а доповнює їх. Ті самі дані можуть одночасно використовуватися в SQL‑звітах, BI‑дашбордах і в AI‑чаті. MongoDB забезпечує стабільне зберігання, Qdrant — семантичний пошук, OpenAI — інтелектуальну інтерпретацію запитів, а LangChain — координацію всього процесу.
Висновок: скрепінг як основа для власних доменних AI‑систем
Проєкт Amazon Price Scraper у виконанні Tech With Tim показує, як змінюється роль скрепінгу в епоху LLM. Замість того щоб бути разовим інструментом для отримання таблиці, він стає джерелом даних для власної доменної AI‑системи.
Зберігаючи scraped‑продукти в MongoDB як основне джерело істини, паралельно вбудовуючи їх у Qdrant, використовуючи OpenAI для ембедингів і відповідей, а LangChain — для побудови агента з інструментами, архітектура перетворює «сирі» HTML‑сторінки Amazon на запитувану вільною мовою базу знань про товари й ціни.
Головний ефект такого підходу — довгострокова цінність даних. Усе, що колись було зібрано, не губиться в архівах, а залишається доступним через AI‑шар, який можна розвивати, доповнювати й інтегрувати в бізнес‑процеси. Для компаній, що працюють з e‑commerce, це означає можливість будувати власні «розумні» інструменти конкурентної розвідки, не покладаючись на сторонні платформи.
Джерело
How to Design a Production-Grade System in Python — Tech With Tim