
Последнее десятилетие ознаменовалось значительным улучшением возможностей компьютеров воспринимать мир вокруг. Программное обеспечение способно быстро распознавать лица людей, заменять людей на фото и видео, подделывать голоса в аудио. Смартфоны могут служить переводчиками реального времени и редактировать фото «на лету», а автомобили научились ездить без водителя. Роботы разносят еду, выступают в парламенте и угрожают уничтожить человечество. Такие возможности стали реальностью благодаря технологии под названием глубокое обучение. В ее основе – нейронные сети, и вот как они работают.

Быстро о компьютерных нейросетях
Компьютерные нейросети – это такая структура данных, которая напоминает структуру нейросети биологического существа. Искусственные нейросети также организованы в слои, выход одного слоя подключен ко входу следующего слоя.

Ученые начали экспериментировать с искусственными нейросетями еще в 1950-х годах. Стать такими, как мы их знаем сегодня, нейросети смогли благодаря двум большим прорывам в 1986 году и 2012 году. Последний стал революцией глубокого обучения, который перенес результаты работы нейросетей на качественно новый уровень. Этот прорыв стал возможным благодаря росту объемов данных и вычислительной мощности компьютеров.
Нейросети в 1950-х
В 1957 году ученый Университета Корнелла Фрэнк Розенблатт опубликовал статью с описанием нейросети, которые он назвал перцептроном. В 1958 году с помощью ВМС США он построил рабочий прототип, который анализировал изображение размером 20х20 пикселей и распознавал простые геометрические формы.
Підписуйтесь на наш канал у Telegram: https://t.me/techtodayua
«ВМС сегодня открыло зародыш электронного компьютера, который сможет ходить, видеть, говорить, писать, воспроизводить себя и быть сознательным относительно своего существования», – писал тогда журналист The New York Times.
Фундаментально каждый нейрон – лишь математическая функция. Он вычисляет общий вес сигналов на своем входе, который служит основой для расчета нелинейной функции, называемой функцией активации.
Особенность перцептрона Розенблатта – в возможности «учиться» на примерах. Нейросеть тренируют корректировать расчет веса сигналов на входе на заданных примерах. Если нейросеть правильно распознает заданный образ – вес увеличивают. Если распознавание неправильное – вес уменьшают.
В 1960-х перспективы нейросетей казались радужными, но ученые Марвин Мински и Сеймур Паперт в своей книге 1969 года показали, что ранние нейросети имели существенные ограничения. Те нейросети имели один-два слоя, и Мински и Паперт показали, что они неспособны моделировать сложные явления реального мира.
Стало очевидно, что нужно развивать глубокие нейросети с гораздо большим количеством слоев. Однако на пути стали ограниченные вычислительные возможности компьютеров того времени. Также еще не изобрели простой алгоритм для тренировки глубоких нейросетей.
В период 1970-х и ранних 1980-х нейросети уже не воспринимались как прорывные. Пока в 1986 году не опубликовали статью с описанием практического метода тренировки глубоких нейросетей — метода обратного распространения ошибки.
Представьте, что вы программист, которому нужно создать программу, распознающую наличие хот-дога на фотографии. Вы запускаете нейросеть, которая на входе получает изображение, а на выходе выдает результат 0 (отсутствие хот-дога на фото) и 1 (наличие хот-дога на фото).
Для тренировки нейросети вы собираете тысячи фотографий и проставляете на них метку наличия хот-дога. Первое из этих фото направляется на вход нейросети. Например, на нем есть хот-дог, но нейросеть выдала значение 0,07. Это почти 0, что означает отсутствие хот-дога. Это неправильный ответ – нейросеть должна была выдать значение близкое к 1.
По алгоритму 1960-х годов веса на входе в нейросеть корректируются так, чтобы при повторном анализе этой картинки нейросеть выдавала правильный ответ. Это было легко сделать вручную, если нейросеть имела один-два слоя. При значительном увеличении слоев появлялось слишком много переменных.
По методу обратного распространения ошибки алгоритм сам обсчитывал небольшое изменение во входных весах каждого слоя нейросети так, чтобы получить максимального приближенный к правильному результат. Это дает таблицу погрешностей на каждом слое нейросети, по которой можно корректировать веса нейронов. Алгоритм повторяется снова и снова, корректируя входные веса нейронов.
Метод обратного распространения ошибки позволил создавать нейросети с десятками и сотнями слоев. При этом нейросети могли иметь сложную внутреннюю структуру.
Этот метод открыл вторую волну развития нейросетей и их практическое использование. В 1998 исследователи AT&T показали, как использовать нейросети для распознавания рукописных цифр и автоматической обработки бумажных чеков.
В те годы нейросети все еще оставались одной из альтернатив. Студентам преподавали также восемь других возможных алгоритмов машинного обучения.
Большие данные показали возможности нейросетей
Метод обратного распространения ошибки позволил эффективно тренировать масштабные нейросети, но оставался вопрос вычислительной мощности компьютеров. В 2012 году Алекс Крижевски описал нейросеть AlexNet, показав, что можно получить прорыв в производительности, если иметь огромные массивы данных. AlexNet имела 8 слоев, 650 000 нейронов, 60 млн параметров.
Нейросеть AlexNet создали три ученых Университета Торонто в рамках академического конкурса ImageNet. Для него организаторы «обчистили интернет», собрав 1 млн фотографий. Эти снимки были промаркированы по категориям в соответствии изображенного – вишня, корабль, леопард и тому подобное.
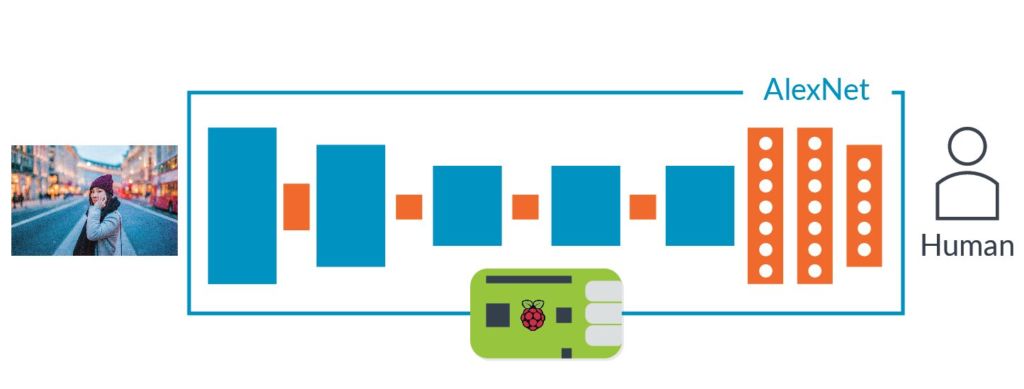
Задачей конкурса было создать нейросеть, которая могла правильно классифицировать картинки, не встречавшиеся ей раньше. К 2012 году лучший результат был 25% погрешностей. Однако AlexNet показал 16% погрешностей. Ближайший соперник имел 26% погрешностей.
Авторы AlexNet привлекли несколько технологий, одной из которых было использование сверточных нейросетей. Последние эффективно тренируют небольшие нейросети, которые на вход получают изображения не более 7-11 пикселей на каждую сторону и ищут их по всему большому снимку.
Другим достижением AlexNet было использование видеокарт для тренировки. Видеокарты хорошо приспособлены для одновременного выполнения многих одинаковых действий. Именно таким является процесс тренировки нейросети.
AlexNet также помог огромный набор подготовленных для конкурса ImageNet фотографий. Имея миллион снимков, авторы нейросети смогли точно настроить 60 млн параметров нейросети.
Все три элемента успеха AlexNet существовали задолго до появления этой нейросети. Но именно в AlexNet их использовали одновременно, что позволило нейросети показать лучшую эффективность.
Бум глубокого обучения
Успех AlexNet не остался незамеченным, и глубокое обучение стало вытеснять другие алгоритмы. Нейросети быстро становились эффективнее: с 16% погрешностей в 2012 году они улучшились до 2,3% погрешностей в 2017 году.
Началась коммерциализация технологии глубокого обучения. В 2013 году Google выкупил стартап, который основали авторы AlexNet. И нейросеть и ее решения стали основой для поиска по картинкам в Google Картинки. В 2014 году Facebook начала экспериментировать с технологиями распознавания лиц. С 2016 года Apple использует глубокое обучение для этой же цели в приложениях iOS. Голосовые помощники Apple Siri, Amazon Alexa, Microsoft Cortana, Google Assistant также базируются на глубоком обучении.
Для ускорения работы нейросетей компании также начали разрабатывать специализированные чипы. Google в 2016 создал процессор Tensor Processing Unit. В том же году Nvidia объявила об архитектуре Tesla P100 с оптимизацией для нейросетей. В 2017 году Intel выпустила собственный чип с искусственным интеллектом, а в 2018 такой же создала Amazon. Microsoft сейчас работает над таким чипом.
Глубокие нейросети способны распознавать широкий набор сложных объектов без подробных инструкций от человека. В ближайшие годы ожидается дальнейшее расширение их возможностей.
По материалам: Arstechnica