
Программные средства с открытым исходным кодом (FOSS), значительно упрощающие рутинные операции, занимают особое место среди современных ИТ-решений. Среди таких инструментов ярким примером является Paperless-ngx — система для управления документами, которая обеспечивает надлежащую организацию счетов, налоговых деклараций, квитанций и других записей, устраняя их беспорядочное хранение в электронных письмах и многочисленных папках. Ключевым преимуществом этой платформы является возможность существенного расширения её функционала, включая оптическое распознавание символов (OCR) и анализ документов, с помощью вспомогательных сервисов на основе больших языковых моделей (LLM), таких как Paperless-GPT. Важно отметить, что Paperless-GPT, несмотря на поддержку облачных решений, также демонстрирует высокую эффективность при работе с локально размещёнными коллекциями больших языковых моделей, в частности Ollama.
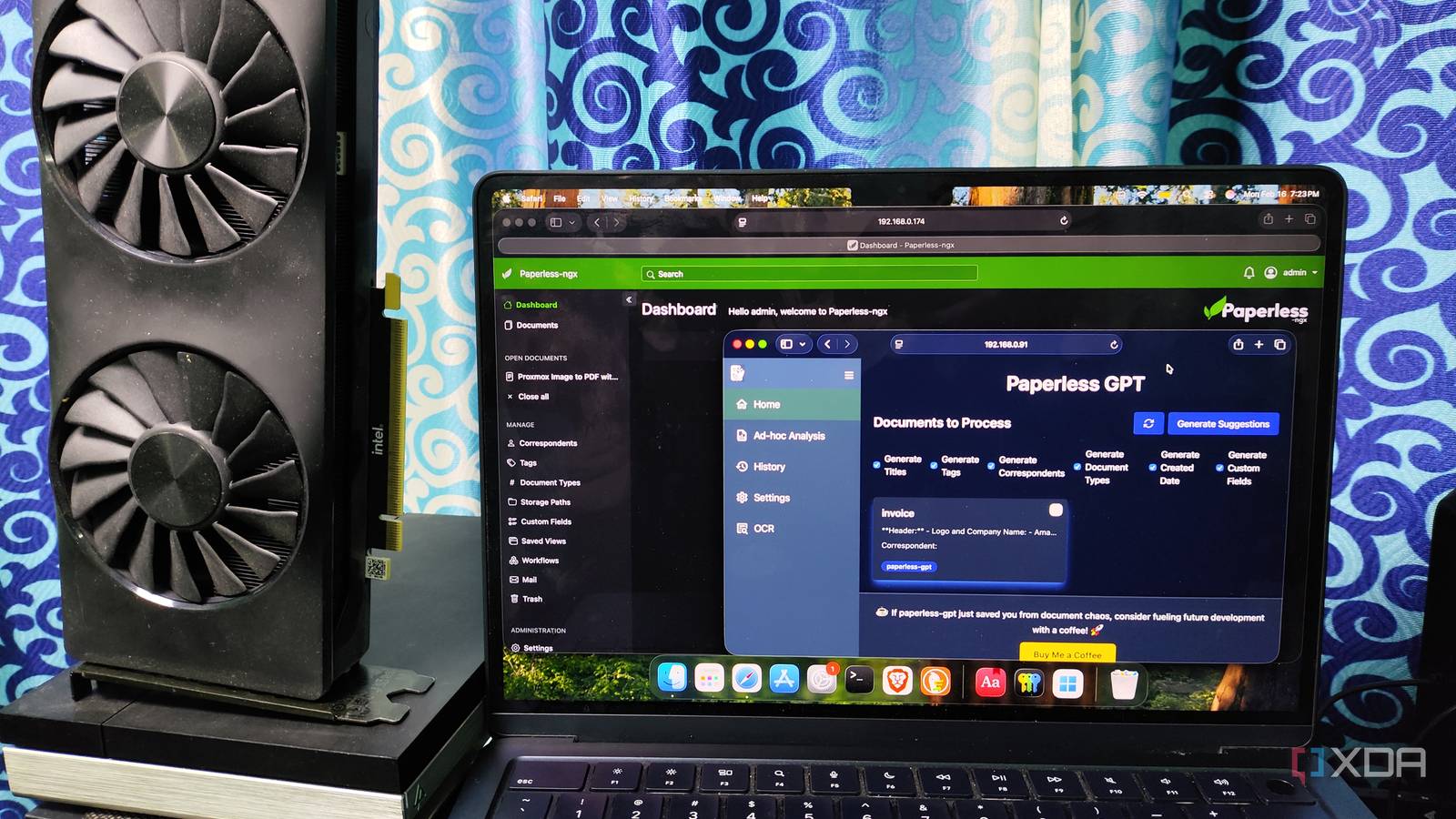
Базовая утилита Paperless-ngx сама по себе является вполне функциональной, однако её встроенное оптическое распознавание символов (OCR) имеет определённые ограничения. При наличии большого количества визуальных элементов или таблиц в документе система может некорректно интерпретировать данные, вставляя случайные и бессмысленные символы вместо распознанного текста. До внедрения Paperless-GPT пользователям часто приходилось вручную редактировать распознанные данные OCR или использовать собственные теги и заголовки для дальнейшей идентификации документов. Paperless-GPT радикально улучшает возможности оптического распознавания символов благодаря интеграции больших языковых моделей, что значительно повышает точность распознавания текста. Хотя система поддерживает интерфейс программирования приложений облачных сервисов, особая эффективность достигается при использовании локальных визуальных больших языковых моделей, обеспечивая надёжное распознавание, в частности текста с низкокачественных фотографий, несмотря на редкие случаи некорректной интерпретации хаотично расположенных данных. Благодаря интеграции с Paperless-ngx, Paperless-GPT автоматически обрабатывает файлы, помеченные соответствующим тегом, а после завершения работы отправляет сгенерированное содержимое обратно в Paperless-ngx, устраняя необходимость в ручном копировании и вставке.
Помимо улучшения оптического распознавания символов, Paperless-GPT использует возможности локальных больших языковых моделей для расширенного автоматизированного управления документами. Система способна генерировать заголовки, теги, имена корреспондентов, даты и даже специальные поля для документов, автоматически интегрируя эти изменения в файлы, хранящиеся в Paperless-ngx. Хотя общие результаты этих функций являются довольно положительными, стоит отметить, что другой инструмент, Paperless AI, показывает лучшие показатели в автоматической генерации тегов. Paperless-GPT также содержит инструмент для ситуативного анализа, что является чрезвычайно полезным для быстрого получения контекста многостраничных документов без необходимости их детального изучения. Хотя стандартный запрос для анализа ориентирован на счета, его можно настроить для создания резюме практически для любого типа документов, включая гарантийные талоны, пресс-релизы или другие материалы, не относящиеся к финансовым операциям. Возможность настройки запросов распространяется на все инструменты Paperless-GPT, такие как генератор заголовков, автоматические теги и оптическое распознавание символов.
Для полноценного функционирования Paperless-GPT в качестве вспомогательной утилиты необходимо наличие активного экземпляра Paperless-ngx, с которого будет осуществляться выгрузка документов. Доступ к Paperless-ngx обеспечивается через его единый указатель ресурсов (URL) и ключ интерфейса программирования приложений (API-ключ), который можно сгенерировать в настройках профиля пользователя. Кроме того, для использования возможностей искусственного интеллекта Paperless-GPT требуется поставщик больших языковых моделей, что может быть реализовано как через облачные сервисы, так и с помощью локальных решений. Внедрение локальных больших языковых моделей, например, через Ollama LXC (контейнер Debian с Ollama и соответствующими моделями), требует конфигурации файла `ollama.service` путём добавления строки `Environment=»OLLAMA_HOST=0.0.0.0″`, что делает его доступным для контейнера Paperless-GPT. После подготовки всех необходимых условий развёртывание контейнера Paperless-GPT осуществляется с помощью файла `compose.yml`, подробный конфигурационный файл которого доступен на странице Paperless-GPT в GitHub, что упрощает настройку, требуя лишь изменения единого указателя ресурсов Paperless-ngx, токена интерфейса программирования приложений и переменных Ollama перед запуском `docker compose up -d`.
Помимо Paperless-GPT, существует ещё один эффективный инструмент для управления документами — Paperless AI, который может дополнительно упростить организацию записей. Хотя Paperless-GPT демонстрирует более высокие возможности в оптическом распознавании символов, Paperless AI отличается поддержкой функционала RAG-чата (Retrieval-Augmented Generation), что позволяет находить документы в Paperless-ngx по контексту запроса. Этот инструмент также предлагает улучшенные механизмы автоматического тегирования и эффективно взаимодействует с самостоятельно размещёнными большими языковыми моделями, предоставляя пользователям дополнительные преимущества для оптимизации рабочих процессов.