
Якщо ви читали матеріал «Що робить ChatGPT і чому він працює? Зазираємо під капот у магію ціє нейромережі», ви розумієте, як ШІ генерує текст. Узагальнено, ШІ на основі підказки юзера та шукає найпопулярніші пов’язані слова за вказаною користувачем темою. Наприклад, ШІ продовжить фразу «чорний кіт» як «чорний кіт нявкає», бо «нявкає» – популярне слово, що в текстах розміщене поруч з котами. ШІ не виведе «чорний кіт кукарікає», бо в текстах людства, на яких його навчено, подібне поєднання слів не вживається.
Але як ШІ створює вражаюче детальні та реалістичні фото і відео на основі текстової підказки? Який набір пікселів пов’язаний, наприклад, з фразою «онлайн-новини»? Тим часом, будь-яка дифузійна ШІ-модель легко згенерує вам картинку за цією фразою-підказкою. Для генерації мультимедійного контенту використовується кмітливі підходи, наприклад, плин часу розвертають у зворотній бік.
Вектори у ШІ: зрозуміло «на пальцях»
Коли мова заходить про штучний інтелект, одразу починається словесна злива із фраз вектори та векторизація. Не лякайтеся, якщо ви востаннє чули про вектори в школі чи університеті – математика вам не потрібна для розуміння.
Вам потрібно лише пам’ятати, що вектор – це лінія з напрямком руху. На папері математики малюють вектор як стрілку.
Просто уявіть, що уся математика та усі числа – це лише спосіб визначити відстань між сутностями. У вас не викликає когнітивного дисонансу фраза «відстань між містами Київ та Харків – 400 км». Ви знаєте, що хтось узяв лінійку та перевів відстань на поверхні планети у коротке число.
Точно так само можна у числовому вигляді назвати відстані між іншими сутностями. Скажімо, яка відстань на гамі кольорів між бордовим та теракотовим? Прикладіть колориметр по черзі до обох відтінків та отримаєте числову відстань між двома кольорами.
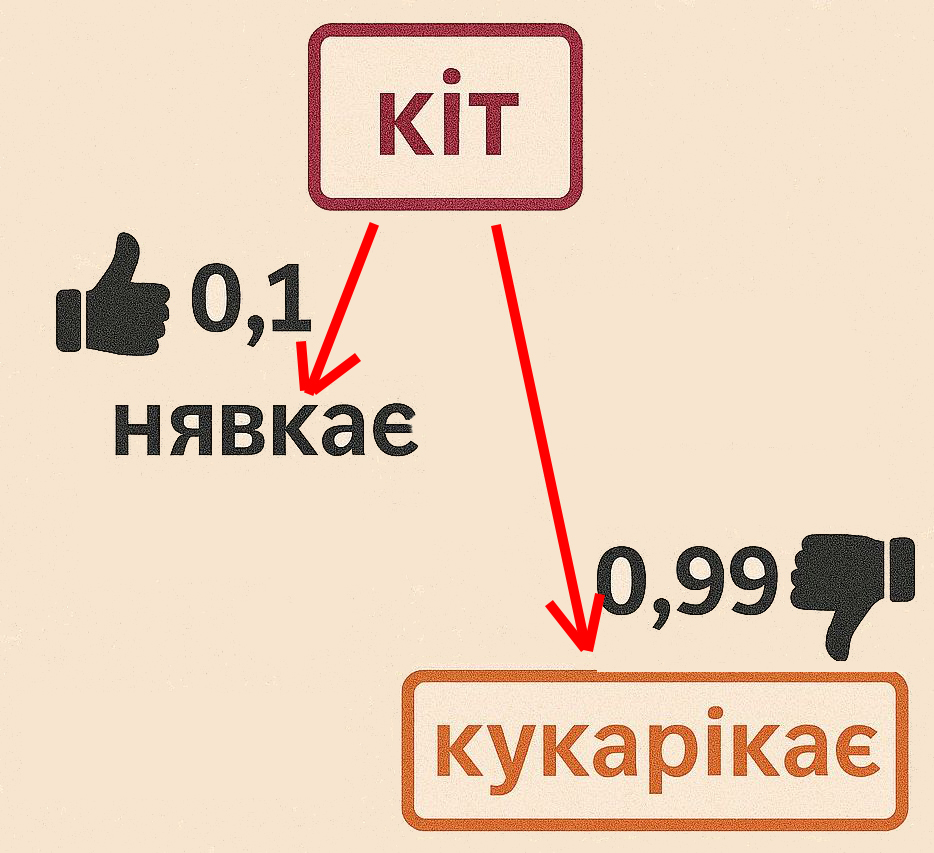
 При навчанні штучного інтелекту створюється така собі мапа відстаней між усіма сутностями, з якими його познайомили. Наприклад, відстань від слова «кіт» до слова «нявкає» становитиме 0,1, тоді як відстань між «кіт» та «кукарікає» складе 0,99. Оскільки слово «нявкає» набагато ближче до слова «кіт», ШІ обере між словами «нявкає» та «кукарікає» саме слово «нявкає». Слово «нявкає», у свою чергу, також має відстань до усіх інших слів.
При навчанні штучного інтелекту створюється така собі мапа відстаней між усіма сутностями, з якими його познайомили. Наприклад, відстань від слова «кіт» до слова «нявкає» становитиме 0,1, тоді як відстань між «кіт» та «кукарікає» складе 0,99. Оскільки слово «нявкає» набагато ближче до слова «кіт», ШІ обере між словами «нявкає» та «кукарікає» саме слово «нявкає». Слово «нявкає», у свою чергу, також має відстань до усіх інших слів.
Тепер час зануритися у те, як ШІ перетворює слова на пікселі.
Приклад роботи ШІ-генератора картинок та відео
У самій назві дифузійних ШІ-генераторів зображень лежить глибокий зв’язок із фізикою. Покоління моделей зображень і відео, яке ми бачимо сьогодні, працює за принципом, відомим як дифузія.
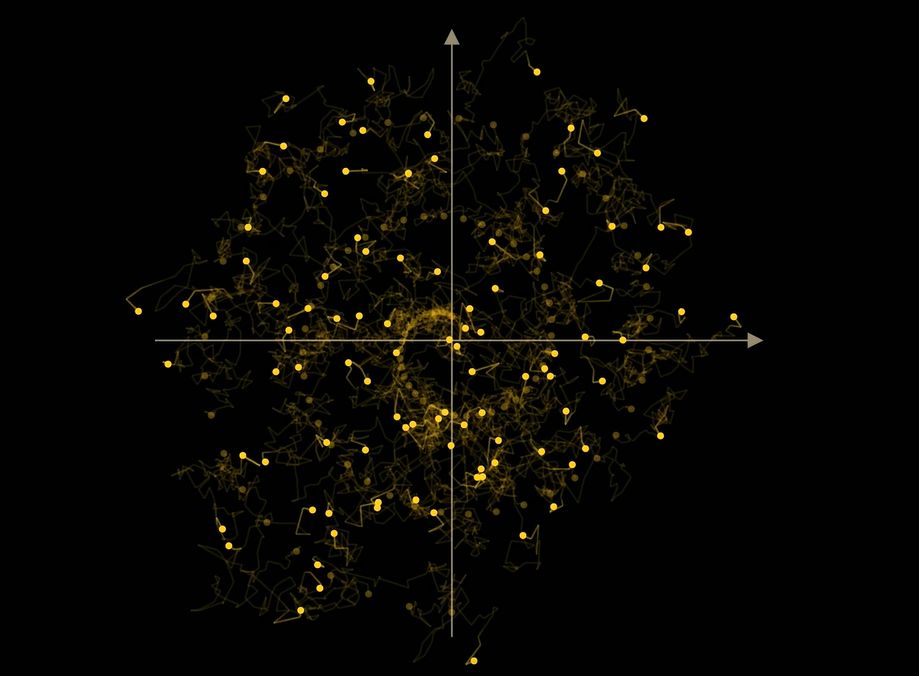
Цей процес вражаюче подібний до броунівського руху, який ми спостерігаємо в природі, коли частинки хаотично рухаються. Але ШІ робить дифузію у зворотному плині часу – від кінця до початку.
Цей зв’язок із фізикою – це не просто цікава аналогія. Із нього прямо випливають алгоритми, за допомогою яких ми можемо створювати зображення та відео. Такий підхід також дає інтуїтивне розуміння того, як ці моделі працюють на практиці.
Але перш ніж зануритися у фізичні основи, розглянемо реальну дифузійну модель.
Якщо заглянути у вихідний код дифузійного ШІ-генератора WAN 2.1, побачимо, що процес створення відео починається з отримання випадкового числа.
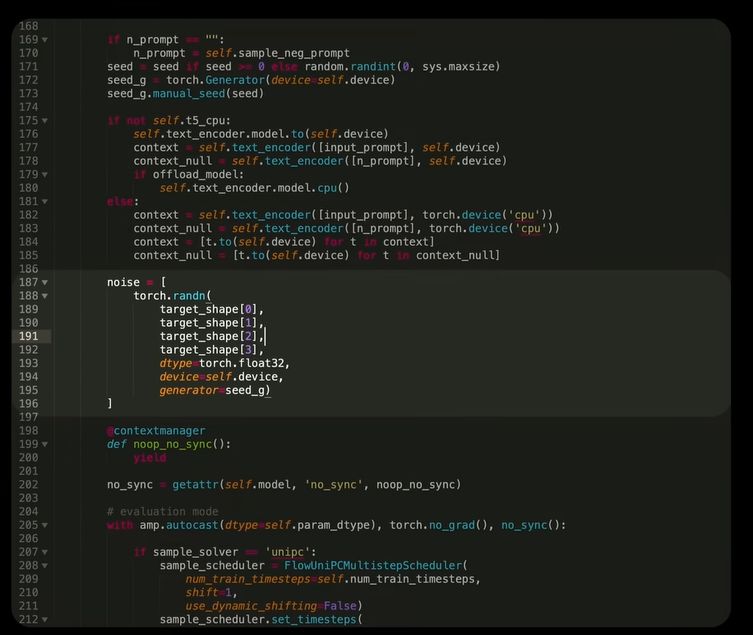
Тобто спочатку ШІ створює просто випадковий набір пікселів, використавши отримане число для початкової підказки. Це зображення виглядає як чистий шум.

Далі цей “шумовий” відеопотік подається у ШІ-модель з назвою трансформер – той самий тип моделей, що лежить в основі великих мовних систем, таких як ChatGPT.
Але замість тексту трансформер видає інше відео – вже з натяками на структуру. Потім це відео додається до початкового відео, і результат знову передається в модель.
Цей процес повторюється десятки разів. Після десятків або сотень повторень із чистого шуму поступово формується напрочуд реалістичне відео.
Але як усе це пов’язано з броунівським рухом? І як модель так точно використовує текстові запити, щоб перетворювати шум у відео відповідно до опису?
Щоб розібратися, розглянемо дифузійні моделі у трьох частинах.
Спочатку дослідимо модель CLIP, створену в OpenAI у 2021 році. Побачимо, що CLIP фактично складається з двох моделей – мовної та візуальної, які навчаються разом так, щоб утворити спільний простір відстаней між словами та зображеннями.
Далі розберемо сам процес дифузії – як моделі навчаються видаляти шум і перетворювати хаос у зображення. Ми побачимо, що просте уявлення “модель просто прибирає шум” не зовсім відповідає реальності.
І нарешті, поєднаємо CLIP і дифузію, щоб зрозуміти, як саме текстові запити керують створенням зображень і відео.
CLIP
2020 рік став переломним для мовного моделювання. Результати досліджень масштабування нейронних мереж і поява GPT-3 показали, що “більше” дійсно означає “краще”.
Величезні ШІ-моделі, навчені на гігантських наборах даних, виявили здатності, яких просто не існувало в менших моделях.
Дослідники швидко застосували ті ж ідеї до зображень.
У лютому 2021 року команда OpenAI представила модель CLIP, навчення якої базувалося на 400 мільйонах пар “зображення – текстовий підпис”, зібраних з інтернету.
CLIP складається з двох моделей: одна обробляє текст, інша – зображення.
Вихід кожної – це вектор довжиною 512, і головна ідея полягає в тому, що вектори для одного зображення та його підпису мають бути схожими.
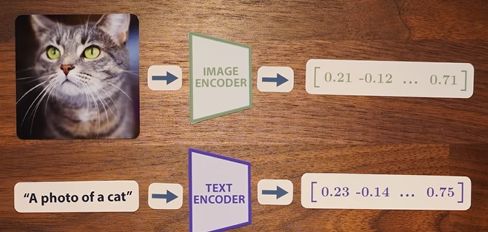
Для цього було розроблено контрастивну схему навчання.
Наприклад, у наборі даних може бути фото кота, собаки і людини, з підписами “фото кота”, “фото собаки” і “фото чоловіка”.
Три зображення передаються у візуальну модель, а три тексти – у текстову. Ми отримуємо шість векторів(чисел відстані з напрямком руху) і хочемо, щоб пари, які відповідають одне одному, мали найбільшу схожість (мали найменшу відстань).
При цьому враховується не лише схожість відповідних пар, а й відмінність між усіма іншими комбінаціями.
Розмістимо вектори для зображень можна як стовпці матриці, а для текстів – рядки.
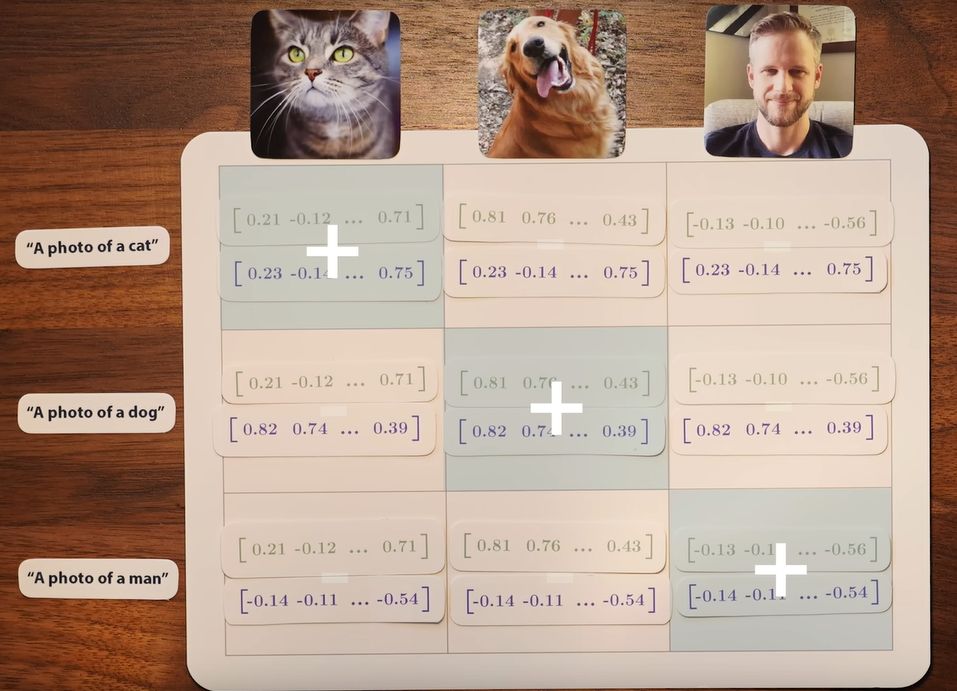
Пари на діагоналі – це правильні збіги, а поза нею – неправильні. Мета CLIP – максимізувати схожість правильних пар і мінімізувати схожість неправильних.
Це “контрастивне” навчання і дало моделі її назву: Contrastive Language-Image Pre-training (CLIP).
Схожість вимірюється за шкільною формулою – косинус кута між двома лініями (векторами). Якщо кут між векторами дорівнює нулю, їх косинус дорівнює 1 – це максимальна схожість.
Отже, CLIP навчається так, щоб пов’язані тексти і зображення “дивилися” в один напрямок у спільному просторі.
Маючи відстані між певними сутностями, ШІ може продукувати проміжні результати. Наприклад, якщо взяти дві фотографії однієї людини: з капелюхом і без, і обчислити різницю відстані між їхніми векторами, то результат відповідатиме поняттю “капелюх”.

Тобто віднімаючи та додаючи відстані (вектори) виявляється можливим працювати з концептами, а не просто над зображеннями.
CLIP також може класифікувати зображення: достатньо порівняти його числову відстань із набором відстаней для можливих підписів і вибрати ту, що має найбільшу схожість.
Таким чином, CLIP створює потужний простір, в якому картинки пов’язані з текстом. Але це працює лише в одному напрямку: від даних до векторів, а не навпаки.
Дифузійні ШІ-моделі
Того ж 2020 року команда з Берклі опублікувала роботу Denoising Diffusion Probabilistic Models (DDPM). У ній було вперше показано, що можна генерувати зображення високої якості, перетворюючи шум на зображення поступово, крок за кроком.
Ідея проста: ми беремо набір навчальних зображень і додаємо до них шум, поки вони не зруйнуються повністю. Потім навчаємо мережу виконувати зворотний процес – прибирати шум.
Проте пряма реалізація “прибираємо шум по кроках” працює погано. Дослідники з Берклі запропонували іншу схему: беремо “чисте зображення”, спотворюємо його та йдемо у зворотньому напрямку – від шуму до початкового зображення.

Цей підхід працює значно краще, ніж поступове відновлення.
Також важливо, що під час генерації модель знову додає шум на кожному кроці – і саме це робить результати чіткішими.
Причина пояснюється теорією броунівського руху: додавання випадкового шуму допомагає уникнути “злипання” точок у центрі розподілу даних і відтворює їх повне різноманіття.
У результаті замість середнього розмитого зображення ми отримуємо безліч реалістичних варіантів.
ШІ створює картинки, запускаючи час в зворотному напрямку
Дифузійні моделі можна інтерпретувати як навчання часозалежного векторного поля, яке вказує напрямок, у якому потрібно рухатися від шуму до даних.
Уявімо двовимірний приклад, де кожна точка – це маленьке зображення з двох пікселів. Якщо ми додаємо шум, точка робить випадкові кроки – це і є броунівський рух.
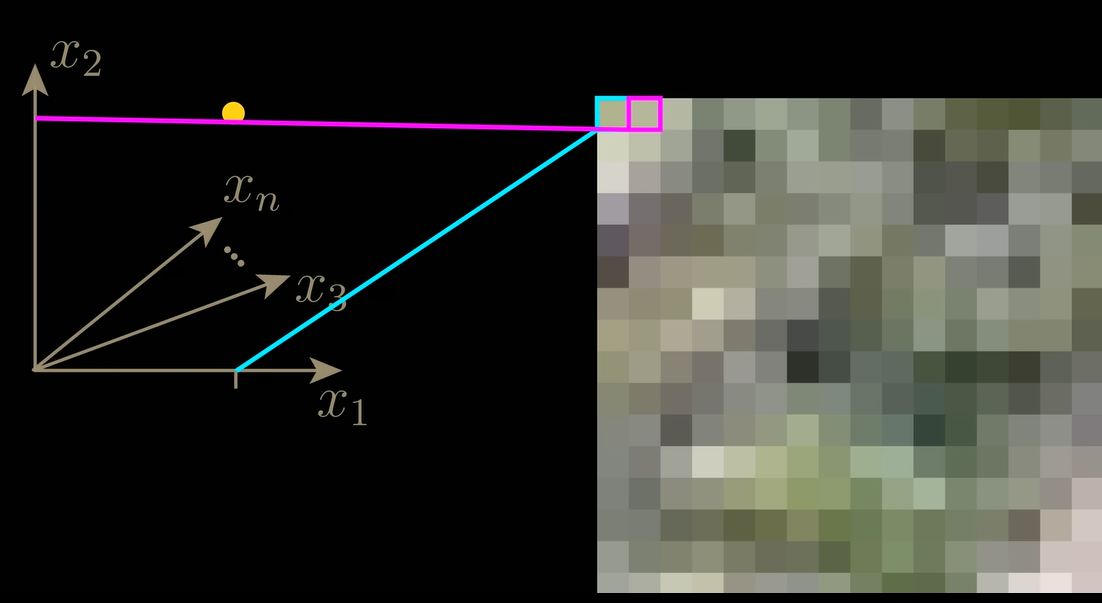
Модель навчається “крутити годинник назад”, повертаючи точки назад до вихідної структури (наприклад, спіралі).
Якщо ми навчимо її не лише за координатами, а й за часом t (кількість кроків), модель навчиться поводитися по-різному на різних етапах – спочатку грубо, потім детальніше.
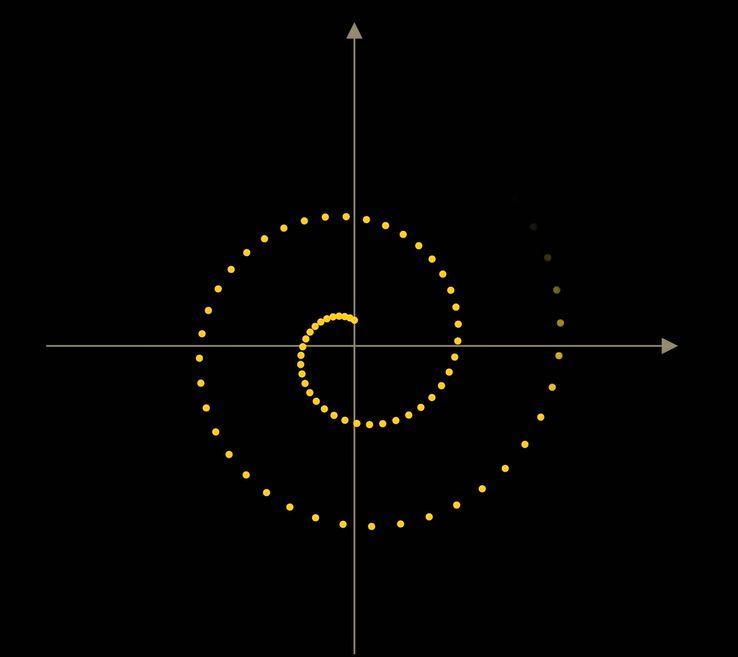
Це робить її набагато ефективнішою.
Додавання шуму під час генерації також випливає з цієї моделі: воно дозволяє зразкам не “злипатись” у середнє значення, а рівномірно заповнювати розподіл даних.
Якщо шум не додавати, модель сходиться до центру – тобто створює “усереднене”, розмите зображення.

DDIM
Незабаром з’явився спрощений метод DDIM (Denoising Diffusion Implicit Models), який довів, що можна отримувати ту саму якість без випадкових кроків.
Він ґрунтується на аналітичному зв’язку між стохастичним рівнянням (з шумом) і звичайним детермінованим диференційним рівнянням без шуму.
DDIM дає змогу генерувати зображення швидше й без втрати якості.
Обидва методи – DDPM і DDIM – приводять до одного й того ж розподілу результатів, але DDIM робить це детерміновано, без випадковості.
WAN використовує подальший розвиток цієї ідеї – метод flow matching.
DALL·E 2 та об’єднання CLIP із дифузією
До 2021 року стало очевидно, що дифузійні моделі можуть створювати зображення високої якості, але не вміють добре реагувати на текстові підказки.
Ідея поєднати CLIP і дифузію виглядала природною: CLIP вміє добре порівнювати слова та картинки та може керувати процесом створення картинок методом дифузії.

У 2022 році команда OpenAI зробила саме це, створивши unCLIP, комерційна версія якого відома як DALL·E 2.
DALL·E 2 навчається перетворювати вектори з CLIP у зображення, і робить це з неймовірною точністю.
Текстові вектори передаються в дифузійну модель як додаткова умова, і вона використовує їх, щоб точніше прибирати шум відповідно до опису.
Цей метод називається conditioning – умовне керування.
Але conditioning сам по собі не гарантує повного відповідності запиту. Для цього потрібен ще один прийом.
Guidance
Повернімося до прикладу зі спіраллю. Якщо різні частини спіралі відповідають різним класам (люди, собаки, коти), то conditioning допомагає, але не ідеально: точки плутаються.
Вирішенням є classifier-free guidance. Модель навчають як із класовою умовою, так і без неї.
Під час генерації ми можемо порівняти вектори для умовної і безумовної моделей. Різниця між ними вказує напрямок до потрібного класу, і ми можемо підсилити цей напрямок коефіцієнтом ? (альфа).
У результаті модель точніше відтворює потрібні об’єкти – наприклад, дерево в пустелі нарешті з’являється і стає дедалі реалістичнішим, якщо збільшувати ?.
Цей принцип став стандартом у сучасних моделях.
WAN застосовує ще цікавіший варіант – негативні підказки (negative prompts).
Тобто користувач може явно вказати, чого він не хоче бачити у відео (наприклад, “зайві пальці” або “рух назад”), і ці фактори віднімаються від результату.
Висновок
Від публікації DDPM у 2020 році до сьогодні розвиток дифузійних моделей відбувався з шаленим темпом. Сучасні системи, здатні перетворювати текст у відео, виглядають як щось майже нереальне.
Найвражаюче те, що всі ці частини – текстові енкодери, векторні поля, зворотні дифузійні процеси – узгоджуються між собою настільки точно, що утворюють цілісний механізм. І все це базується на простих математичних формулах та геометрії. Результатом стали моделі, що нагадують новий тип машини.
Тепер, щоб створити реалістичні й красиві зображення або відео, не потрібна камера, художник чи аніматор. Достатньо лише кількох слів тексту.
За матеріалами: Welch Labs