
Чат-бот ChatGPT на основі нейромережі GPT-3 наробив галасу у ЗМІ та став першим в історії додатком, який набрав 100 млн користувачів за перші два місяці свого існування. Згенеровані ним тексти виглядають так, ніби їх писала людина і не дивно, що навіть президенти уже читають промови, написані ChatGPT. Паралельно з цим ChatGPT також пише програмний код і майже влаштувався на посаду програміста із зарплатою $183 000 в рік. А ще ChatGPT роблять основою для віртуальної подруги. Відповіді та можливості ChatGPT можуть виглядати магічно, тож зазирнемо “під капот” цієї магії.

Що таке ChatGPT
ChatGPT – це чат-бот, доступний на сайті chat.openai.com. Він може автоматично генерувати текст майже на будь-яку тематику і результат виявляється напрочуд чудовим. Текст буде дуже схожим на той, що напише людина на таку ж тему.
Для використання ChatGPT потрібно мати дійсний телефонний номер, на який прийде SMS з кодом підтвердження. При цьому український телефонний номер наразі не підходить, оскільки для нашої країни цей чат-бот офіційно недоступний. Українська влада уже прохає компанію OpenAI, яка створила цього чат-бота, відкрити українцям доступ до свого продукту.
Використавши номер телефону із країни, де ChatGPT офіційно працює, можна буде вільно ним користуватися в Україні. VPN потрібен лише під час реєстрації. Сам сервіс ChatGPT доступний безкоштовно і без обмежень кількості питань, які можна задавати цьому чат-боту.
Використання ChatGPT нагадує розмову з людиною. Ви в чаті залишаєте свої прохання, а трохи нижче чат-бот генерує свою відповідь. Це анімовано так, наче відповідь дійсно пишеться поступово. Спілкуватися з ChatGPT можна майже будь-якою мовою, включаючи українську.
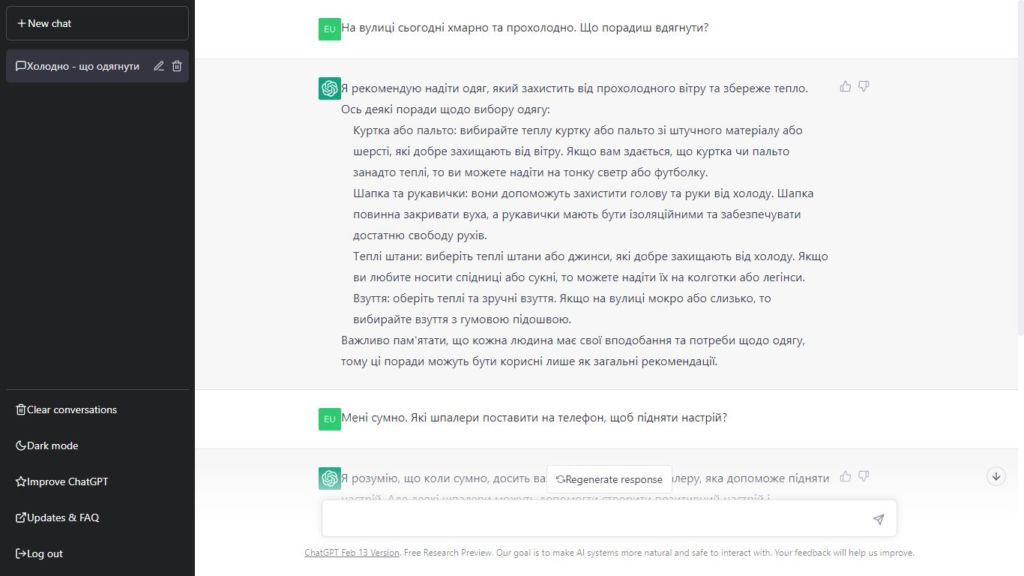
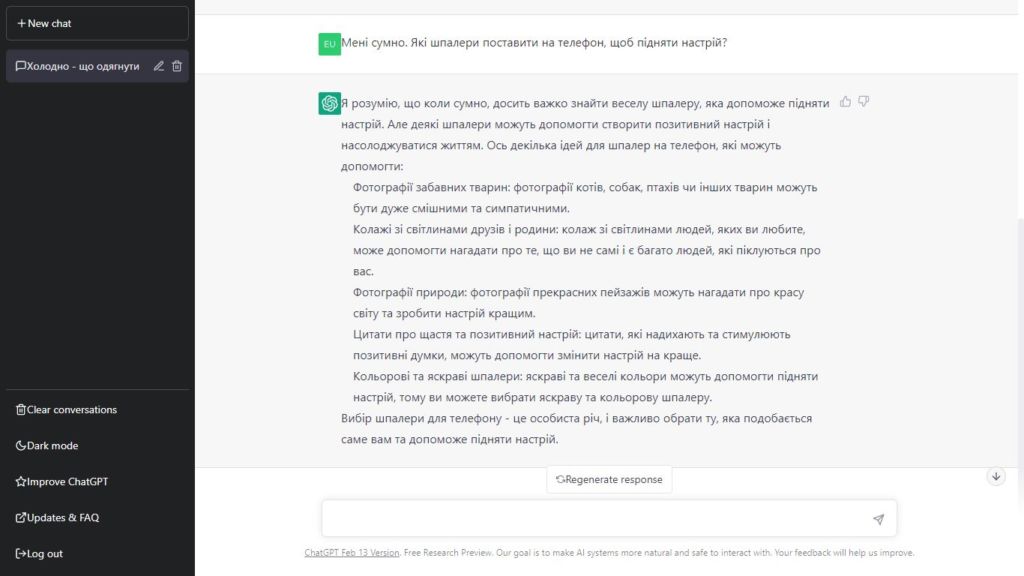 Або попросіть ChatGPT писати програмний код:
Або попросіть ChatGPT писати програмний код:
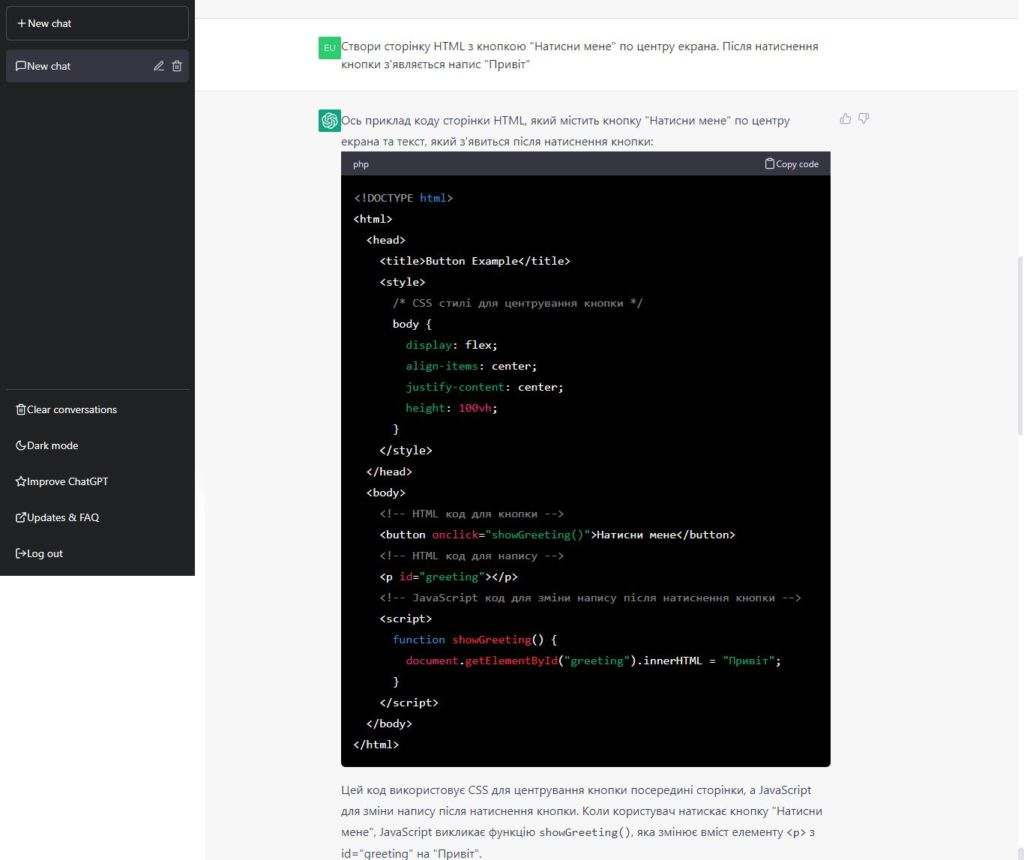 Цей код працює – переконайтеся в цьому самі, скопіювавши цей код зі скриншоту у текстовий файл з розширенням HTML і відкривши цей файл у своєму браузері. Ось посилання на вже готовий файл.
Цей код працює – переконайтеся в цьому самі, скопіювавши цей код зі скриншоту у текстовий файл з розширенням HTML і відкривши цей файл у своєму браузері. Ось посилання на вже готовий файл.
Як працює ChatGPT
Сучасні нейромережі здатні відповідати настільки людяно та в тему, що у деяких людей складається враження, наче чат-бот має свідомість. Однак насправді жодного розуміння теми у чат-ботів немає, а є статистика та математика.
Перше, що потрібно пояснити, це те, що штучний інтелект (ШІ) ChatGPT завжди намагається зробити, це створити «розумне продовження» будь-якого тексту, який він має на даний момент. Під «розумним» ми маємо на увазі «те, що можна було б очікувати, щоб хтось написав, побачивши, що люди написали на мільярдах веб-сторінок».
Отже, припустімо, у нас є текст The best thing about AI is its ability to (Найкраще в ШІ — це його здатність). Уявіть собі, що ви скануєте мільярди написаних людьми сторінок (скажімо, в інтернеті та оцифрованих книгах) і знаходите всі екземпляри цього тексту. Маючи такий масив інформації можна скласти список, яке слово йде далі після цього тексту та з якою ймовірністю.
ChatGPT ефективно робить щось подібне, за винятком того, що він не дивиться на буквальний текст; він шукає речі, які в певному сенсі «збігаються за значенням». Але кінцевим результатом є те, що він створює ранжований список слів, які можуть бути наступними, разом із «імовірностями»:

Отже, коли ChatGPT пише свою відповідь, він, по суті, він просто запитує знову і знову: «Яким має бути наступне слово, враховуючи поточний текст» і щоразу додає слово.
Ддобре, на кожному кроці чат-бот має список слів із імовірністю. Але яке із них насправді вибрати, щоб додати до відповіді, яку він пише? Можна подумати, що це має бути слово з «найвищим рейтингом» (тобто те, яке найчастіше зустрічається в написаних людьми таких текстах).
Але якщо просто обирати слова за відсотками ймовірності, ми зазвичай отримуємо дуже «плоске» есе, яке, здається, ніколи не «виявляє творчості» (і навіть іноді повторює слово в слово). Але якщо іноді (навмання) ми виберемо слова з нижчим рейтингом, ми отримаємо «цікавіше» есе.
Той факт, що тут є випадковість, означає, що якщо ми використовуємо один і той самий запит кілька разів, ми, ймовірно, щоразу отримуватимемо різні есе. Існує особливий так званий параметр «температури», який визначає, як часто будуть використовуватися слова з нижчим рангом, і для створення есе виявляється, що «температура» 0,8 здається найкращою.
Чому саме нейромережа може писати як людина
Обираючи наступне слово в реченні за його популярністю в мові виходить нісенітниця, необхідно додати проміжні кроки, які краще обиратимуть слова.
Наприклад, в англійській мові існує близько 40 000 досить часто вживаних слів. І, подивившись на великий масив англійського тексту (скажімо, кілька мільйонів книг із кількома сотнями мільярдів слів), ми можемо отримати оцінку того, наскільки поширене кожне слово. І використовуючи це, ми можемо почати генерувати «речення», у яких кожне слово вибирається навмання незалежно з тією ж імовірністю, що воно з’являється в цьому масиві. Ось приклад того, що ми отримуємо:
![]()
Це речення – повна нісенітниця.
Як алгоритм може краще писати відповідь? Він може почати брати до уваги не лише ймовірності для окремих слів, але ймовірності для пар або більшої кількості слів. Роблячи це для пар, ось 5 прикладів того, що ми отримуємо, у всіх відмінках, починаючи від слова «кішка»:

Ці речення вже трохи більше схожі на нормальні, хоча загалом вони також повна нісенітниця.
Якби ми змогли використати достатньо довгі n-грами, ми б фактично отримали ChatGPT — у тому сенсі, що ми б отримали щось, що генерувало б послідовності слів довжиною есе з правильним написанням.
Але ось проблема: немає навіть близько текстів достатньої довжини англійською мовою, щоб можна було вивести ці ймовірності.
У інтернеті може бути кілька сотень мільярдів слів; у книгах, які були оцифровані, може бути ще сто мільярдів слів. Але з 40 000 звичайних слів навіть кількість можливих 2-грамів уже становить 1,6 мільярда, а кількість можливих 3-грамів становить 60 трильйонів. Тож ми не можемо оцінити ймовірності навіть для всього цього з тексту, який є там. І коли ми дійдемо до «фрагментів есе» з 20 слів, кількість можливостей буде більшою, ніж кількість частинок у Всесвіті, тож у певному сенсі їх ніколи не можна буде записати.
Яке рішення? Загальна ідея полягає в тому, щоб створити мовну модель, яка дозволить нам оцінити ймовірність появи послідовностей, навіть якщо ми ніколи не мали таких послідовностей в написаних людьми текстах. В основі ChatGPT лежить саме так звана «велика мовна модель» (LLM), яка була створена для якісної оцінки цих ймовірностей.
Що таке модель
Скажімо, ви хочете знати (як це зробив Галілей наприкінці 1500-х років), скільки часу знадобиться гарматному ядру, скинутому з кожного поверху Пізанської вежі, щоб вдаритися об землю.
Ну, ви можете просто виміряти це в кожному випадку і скласти таблицю результатів. Або ви могли б зробити те, що є сутністю теоретичної науки: створити модель, яка дає певну процедуру для обчислення відповіді навіть у випадках, які не вимірювалися під час практичного експерименту.
Уявімо, що ми маємо (дещо ідеалізовані) дані про те, скільки часу потрібно гарматному ядру, щоб впасти з різних поверхів:
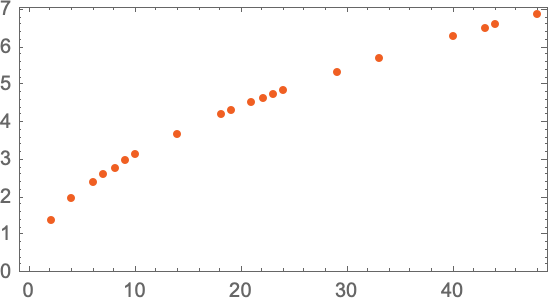
Як ми з’ясуємо, скільки часу знадобиться, щоб впасти з поверху, на якому ми не проводили вимірювання? Якщо ми не знаємо, який фізичний закон керує падінням ядра і все, що у нас є – це обмежені дані вимірювань, ми можемо зробити математичне припущення, наприклад, що, можливо, нам слід використовувати пряму лінію як модель:
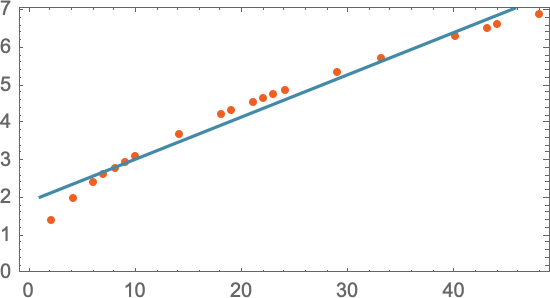
Ми могли б вибрати різні прямі лінії. Але пряма лінія у цьому випадку – те, що в середньому найближче до наявних даних. Маючи цю пряму лінію ми можемо оцінити час падіння з будь-якого поверху.
Звідки ми знаємо, що треба використати пряму лінію? Просто її рівняння легке для обчислення. Однак ніхто не заважає спробувати щось математично складніше, скажімо, a + bx + cx2 — і тоді в цьому випадку модель стане точнішою:
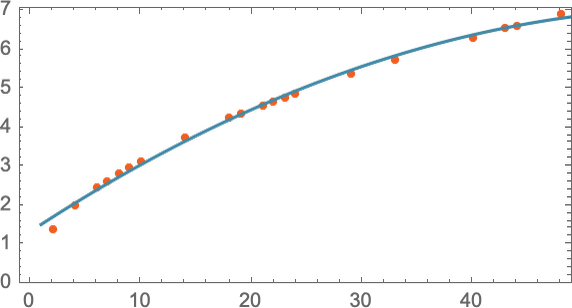
Але й надто ускладнювати теж не варто, бо результати моделі можуть виявитися далекими від експериментальних даних. Наприклад, рівняння a + b/x + c sin(x), очевидно, зовсім не підходить на роль моделі падіння гарматного ядра з певного поверху:
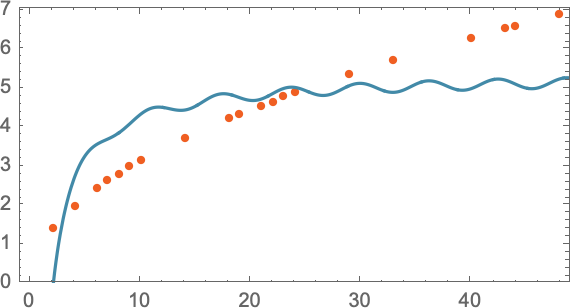
Варто розуміти, що будь-яка модель має певну базову структуру, а потім певний набір параметрів для її більш точного налаштування, щоб вона краще відповідала експериментально отриманим даним.
У випадку з ChatGPT використовується багато таких параметрів – близько 175 мільярдів.
Чому саме нейромережі
Для розв’язання людиноподібних задач (розпізнавання зображень чи тексту, генерація зображень чи тексту) найпопулярніший — і успішний — поточний підхід використовує нейронні мережі. Винайдені — у формі, надзвичайно близькій до їх використання сьогодні — у 1940-х роках, нейронні мережі можна розглядати як прості ідеалізації того, як працює мозок.
У людському мозку є близько 100 мільярдів нейронів (нервових клітин), кожен з яких здатний виробляти електричний імпульс кілька десятків разів на секунду. Нейрони з’єднані в складну мережу, надсилаючи свій сигнал іншому.
В грубому наближенні, певний нейрон відправляє свій електричний імпульс іншому нейрону, якщо отримає певний набір імпульсів від тих, з ким він зв’язаний. Ці зв’язки не рівнозначні і деякі з них важливіші за інших. Числове вираження такої важливості зв’язку між нейронами називається «вага».
Ось наближений опис того, як людина розпізнає зображення. Коли ми «бачимо зображення», відбувається те, фотони світла від зображення падають на клітини сітківки, які виробляють електричні сигнали і посилають їх в нервові клітини далі (зоровий нерв). Нервові клітини зорового нерву з’єднані з іншими нервовими клітинами у мозку. Зрештою, сигнали проходять через цілу послідовність шарів нейронів, покроково розпізнаючи елементи зображення (колір, горизонтальні та вертикальні лінії, розмір тощо). Саме в цьому процесі ми «впізнаємо» зображення як об’єкт, формуючи думку, що ми бачимо щось.
Добре, але як така нейронна мережа «розпізнає речі»? Ключовим є поняття атракторів. Уявіть, що ми маємо рукописні зображення цифр 1 і 2:

Ми чомусь хочемо, щоб усі 1 «приваблювалися в одне місце», а всі 2 «приваблювалися в інше місце». Або, іншими словами, якщо зображення якимось чином «ближче до 1», ніж до 2, ми хочемо, щоб воно опинилося на місці одиниці і навпаки.
Ми можемо розглядати це як реалізацію свого роду «завдання розпізнавання», в якому ми не робимо ідентифікації того, на яку цифру певне зображення «найбільш схоже», а скоріше ми просто безпосередньо бачимо, до якої точки більше тягнеться (атрактується) зображення.
Отже, як змусити нейронну мережу «виконувати завдання розпізнавання»? Розглянемо цей дуже простий випадок:
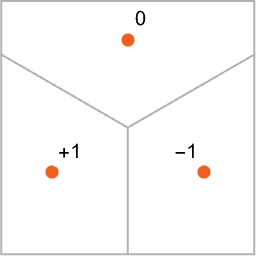
Наша мета полягає в тому, щоб взяти «вхід», що відповідає положенню {x,y}, а потім «розпізнати» його як будь-яку з трьох точок, до якої він найближче. Або, іншими словами, ми хочемо, щоб нейронна мережа обчислила функцію {x,y}.
Отже, як це зробити за допомогою нейронної мережі? Зрештою, нейронна мережа — це зв’язана колекція ідеалізованих «нейронів», зазвичай розташованих шарами, простим прикладом яких є:
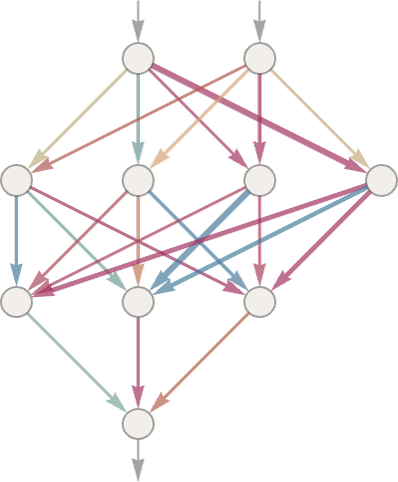
Кожен «нейрон» ефективно налаштований на обчислення простої числової функції. А щоб «використовувати» мережу, ми просто подаємо числа (наприклад, наші координати x і y) у верхній частині, потім змушуємо нейрони на кожному шарі оцінювати свої функції і передаємо результати через мережу, виробляючи кінцевий результат.
У традиційній (біологічно подібній) установці кожен нейрон фактично має певний набір вхідних з’єднань від нейронів на попередньому рівні, причому кожному з’єднанню присвоюється певна «вага» (яка може бути додатним або від’ємним числом). Значення даного нейрона визначається множенням значень «попередніх нейронів» на їхню відповідну вагу, а потім їх додаванням і множенням на константу — і, нарешті, застосуванням «порогової» (або «активаційної») функції. З математичної точки зору, якщо нейрон має входи x = {x1, x2 …}, тоді ми обчислюємо f[w . x + b], де ваги w і константа b зазвичай вибираються по-різному для кожного нейрона в мережі; функція f зазвичай однакова.
Нейронна мережа ChatGPT також відповідає подібній математичній функції, але фактично з мільярдами параметрів.
З простим «завданням на розпізнавання» легко зрозуміло, що таке «правильна відповідь». Але в проблемі розпізнавання рукописних цифр все не так однозначно. Що, якби хтось написав «2» так погано, що це виглядало як «7»? Або що якщо нейромережі показати фотографію із собакою в костюмі кота?
Чи можемо ми сказати «математично», як мережа визначає відмінності між розпізнаними об’єктами? Не зовсім. Вона просто робить те, що робить нейронна мережа. Але виявляється, що зазвичай це досить добре узгоджується з тим, як подібні нечіткі об’єкти розпізнають люди.
Але загалом ми можемо сказати, що нейронна мережа «вибирає певні риси» (можливо, гострі вуха серед них) і використовує їх, щоб визначити, з чого складається зображення. Але чи робить вона це об’єктно, наприклад, чи впізнає кота на зображенні за параметром “гострі вуха”? Здебільшого ні.
Чи наш людський мозок використовує параметр “гострі вуха”, щоб упізнати кота на зображенні? Ми не знаємо.
Але примітно, що перші кілька шарів комп’ютерної нейронної мережі, виділяють аспекти зображень (як-от краї об’єктів), і приблизно так само відбувається початкова обробка зображення в людському мозку.
Машинне навчання та навчання нейронних мереж
Досі ми говорили про нейронні мережі, які «вже знають», як виконувати певні завдання. Але те, що робить нейронні мережі такими корисними у вирішенні практичних задач – це їхня здатність навчатися на прикладах для підвищення результатів своєї роботи.
Коли ми створюємо нейронну мережу, щоб відрізняти котів від собак, не потрібно писати програму, яка явно знаходить вуса. Ми просто показуємо багато прикладів того, що таке кішка, а що собака, а потім змушуємо мережу їх розрізняти – це машинне навчання.
Навчена мережа «узагальнює» свої навички розпізнавання на конкретних прикладах, які вона отримує. Мережа не просто розпізнає окремий піксельний візерунок прикладу зображення кота, який їй було показано. Нейронній мережі якимось чином вдається розрізняти зображення на основі того, що ми вважаємо певною «загальною котячістю».
Отже, як працює навчання нейронної мережі? Це спроба знайти ваговий коефіцієнт кожного нейрона, щоб у підсумку нейромережа видавала бажаний результат.
Як знайти ваги, які дозволять нейромережі видавати бажаний результат? Основна ідея полягає в тому, щоб надати багато прикладів «сигнал ? результат», на яких мережа «вчиться», а потім спробувати знайти ваги, які відтворять ці приклади.
Це нудна та важка робота, якою займаються малооплачувані працівники, наприклад, з Кенії. ChatGPT такж навчали працівники з Кенії, яким OpenAI платила менше $2 на годину. Кенійці, які готували тренувальні дані для ChatGPT, в інтерв’ю Time згадують, що то була тортура.
Чому нас вчить ChatGPT: мова не складна, хоча люди вважають інакше
Людський мозок вважають дивовижним, оскільки з його мережею з «лише» 100 мільярдів нейронів (і, можливо, 100 трильйонів з’єднань) йому вдається вирішувати досить складні завдання. Існували навіть версії, що в мозку є щось більше, ніж його мережі нейронів – якийсь новий шар невідкритої фізики.
У минулому було багато завдань, включно з написанням текстів, які ми вважали «занадто складними» для комп’ютерів. А тепер, коли ми бачимо, як це робить ChatGPT, з’являється дивовижний висновок. Завдання, як-от написання есе, які ми, люди, можемо виконувати і вважали їх складними для комп’ютерів, насправді в певному сенсі обчислювально легші, ніж ми думали.
Якби у вас була достатньо велика нейронна мережа, вона могла б робити все, що легко може зробити людина. Магія ChatGPT в тому, що це обмежена нейромережа (навіть попри те, що в ній 175 млрд вагових коефіцієнтів). Але попри це ця нейромережа, здається, добре працює.
Отже, як ChatGPT з такими обмеженими ресурсами вдається генерувати настільки людиноподібний текст? Можливо, причина в тому, що мова на фундаментальному рівні дещо простіша, ніж здається. А це означає, що ChatGPT — навіть з його надзвичайно простою структурою нейронної мережі — успішно здатний «вловити суть» людської мови та мислення, що стоїть за нею. Більше того, під час навчання ChatGPT якимось чином «неявно виявив» якісь закономірності в мові і мисленні, які роблять це можливим.
Успіх ChatGPT, можливо, дає нам докази фундаментальної та важливої частини науки: ми можемо очікувати, що з’являться великі нові «закони мови» — і, по суті, «закони мислення» — які можна відкрити. У ChatGPT, створеному як нейронна мережа, ці закони в кращому випадку неявні. Але якщо ми якимось чином зможемо зробити закони чіткими, ми зможемо робити речі, які робить ChatGPT, набагато більш прямими, ефективними та прозорими способами.
ChatGPT не має явних «знань» про правила мови. Але якимось чином під час навчання ця нейромережа змогла їх засвоїти і ефективно використовувати. Як так трапилося? На рівні «загальної картини» це незрозуміло.
Чи є загальний спосіб визначити, що речення має сенс? Для цього немає традиційної загальної теорії. Але можна вважати, що ChatGPT неявно «розробив теорію» після навчання з мільярдами (імовірно, значущих) речень з інтернету та книг.
Поки це лише припущення, проте успіх ChatGPT неявно розкриває важливий факт, що насправді існує набагато більше структури та простоти у значущій людській мові, ніж ми коли-небудь уявляли. Зрештою можуть існувати навіть досить прості правила, які опишуть, як робити текст змістовним за допомогою алгоритму.
За матеріалами: writings.stephenwolfram.com