
Если вы прочитали статью Что делает ChatGPT и почему он работает? Заглянем под капот, в магию этой нейронной сети» , вы поймете, как ИИ генерирует текст. В целом ИИ опирается на подсказку пользователя и ищет самые популярные родственные слова по заданной пользователем теме. Например, ИИ будет продолжать фразу «черный кот» как «мяуканье черного кота», потому что «мяу» — популярное слово, которое в текстах ставится рядом с кошками. ИИ не будет выводить «черный кот кукарекает», потому что человек пишет на котором он обучался, не используйте такое сочетание слов.
Но как ИИ создает впечатляюще детализированные и реалистичные фотографии и видео на основе текстовой подсказки? Например, какой набор пикселей ассоциируется с фразой «онлайн-новости»? Между тем, любая диффузионная модель ИИ легко сгенерирует для вас картинку на основе этой ключевой фразы. Для генерации мультимедийного контента используются хитрые подходы, например, поворачивается течение времени.
Векторы в ИИ: четко «под рукой»
Когда дело доходит до искусственного интеллекта, слова «векторы» и «векторизация» сразу же начинают звучать. Не волнуйтесь, если вы в последний раз слышали о векторах в школе или университете — чтобы понять, математика не нужна.
Вам нужно только помнить, что вектор – это линия с направлением движения. Математики рисуют на бумаге вектор в виде стрелки.
Только представьте, что вся математика и все числа — это всего лишь способ определить расстояние между объектами. Фраза «расстояние между городами Киевом и Харьковом 400 км» не вызывает когнитивного диссонанса. Знаете, кто-то взял линейку и перевел расстояние по поверхности планеты в короткое число.
Таким же образом расстояния между другими объектами могут быть названы численно. Скажем, какое расстояние по гамме цветов между бордовым и терракотовым? Примените колориметр поочередно к обоим оттенкам и определите числовое расстояние между двумя цветами.
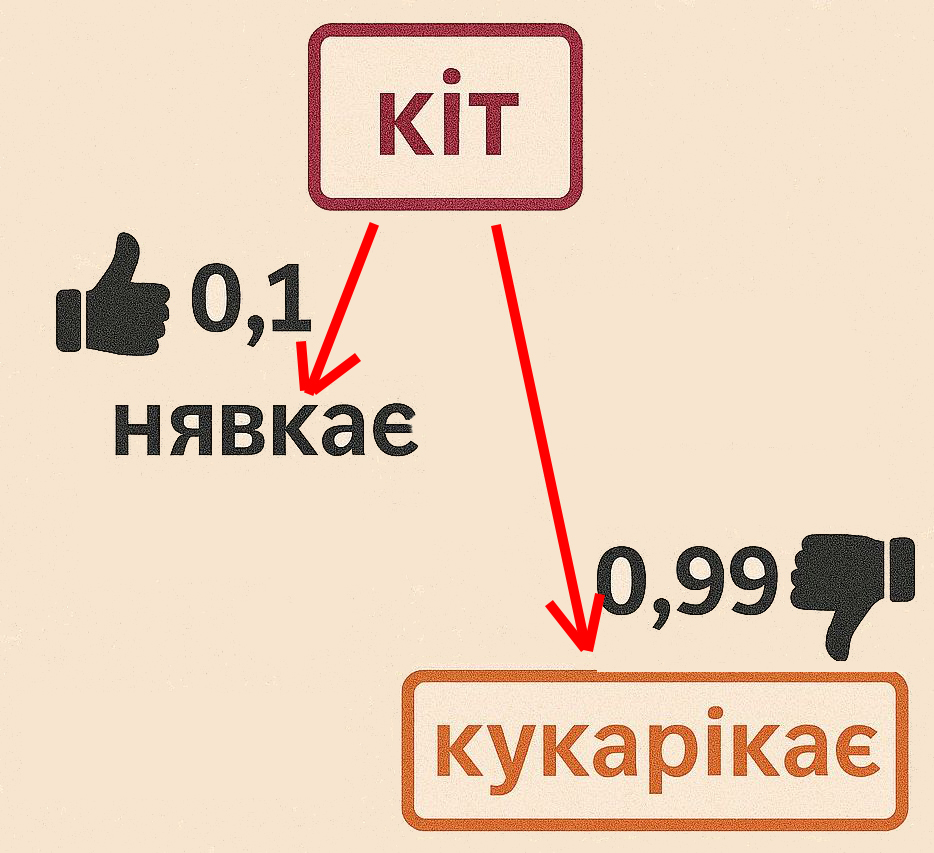
 При обучении искусственного интеллекта создается своеобразная карта расстояний между всеми объектами, с которыми он был знаком. Например, расстояние между словом «кошка» и словом «мяу» будет 0,1, а расстояние между «кошка» и «кукарекает» — 0,99. Поскольку расстояние от слова «мяу» намного меньше, ИИ выберет слово «мяу» между словами «мяу» и «кукарекает». Слово «мяукает», в свою очередь, тоже имеет дистанцию ко всем остальным словам.
При обучении искусственного интеллекта создается своеобразная карта расстояний между всеми объектами, с которыми он был знаком. Например, расстояние между словом «кошка» и словом «мяу» будет 0,1, а расстояние между «кошка» и «кукарекает» — 0,99. Поскольку расстояние от слова «мяу» намного меньше, ИИ выберет слово «мяу» между словами «мяу» и «кукарекает». Слово «мяукает», в свою очередь, тоже имеет дистанцию ко всем остальным словам.
Теперь пришло время погрузиться в то, как ИИ превращает слова в пиксели.
Пример AI-генератора картинок и видео
Само название диффузионных генераторов изображений ИИ имеет глубокую связь с физикой. Генерация моделей изображений и видео, которые мы видим сегодня, работает по принципу, известному как диффузия.
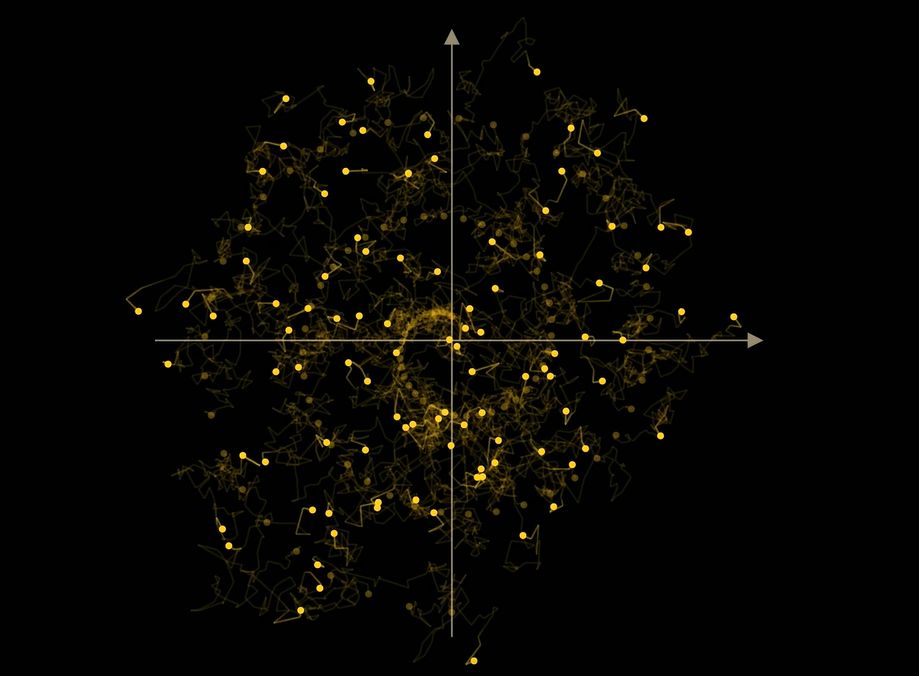
Этот процесс поразительно похож на броуновское движение, которое мы наблюдаем в природе, когда частицы движутся беспорядочно. Но ИИ осуществляет диффузию в обратном потоке времени – от конца к началу.
Эта связь с физикой — не просто интересная аналогия. Из него напрямую вытекают алгоритмы, с помощью которых мы можем создавать изображения и видео. Этот подход также обеспечивает интуитивное понимание того, как эти модели работают на практике.
Но прежде чем погрузиться в физические основы, давайте рассмотрим реальную модель диффузии.
Если мы посмотрим исходный код диффузионного AI-генератора WAN 2.1, то увидим, что процесс создания видео начинается с получения случайного числа.
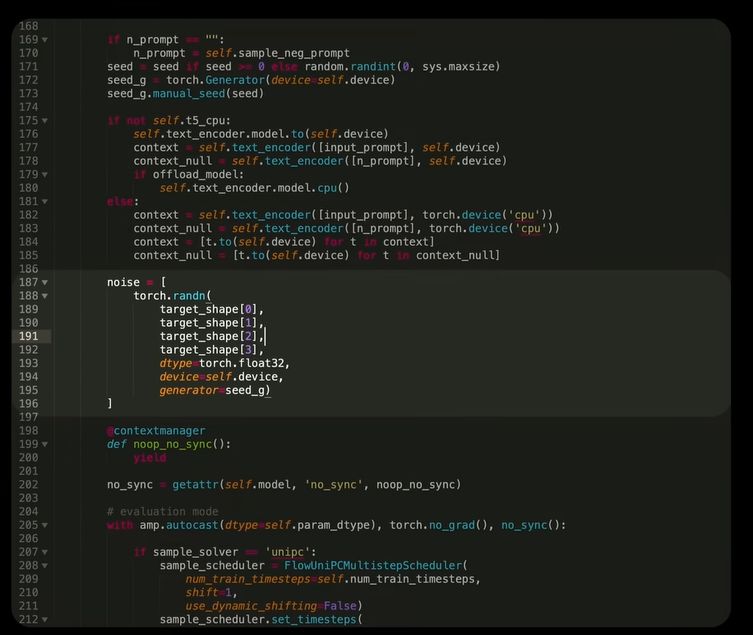
То есть сначала ИИ просто создает случайный набор пикселей, используя полученное число в качестве начальной подсказки. Это изображение выглядит как чистый шум.

Этот «шумный» видеопоток затем подается в модель искусственного интеллекта, называемую преобразователем — модель того же типа, которая лежит в основе больших речевых систем, таких как ChatGPT.
Но вместо текста трансформер выдаёт другое видео — уже с намеками на структуру. Затем это видео добавляется к исходному видео, и результат возвращается в модель.
Этот процесс повторяется десятки раз. После десятков или сотен повторов из чистого шума постепенно формируется удивительно реалистичное видео.
Но как все это связано с броуновским движением? И как модель так точно использует текстовые запросы, чтобы превратить шум в видео, как описано?
Чтобы понять, рассмотрим диффузионные модели в трех частях.
Для начала давайте изучим модель CLIP, созданную в OpenAI в 2021 году. Мы увидим, что CLIP на самом деле состоит из двух моделей — лингвистической и визуальной — которые обучаются вместе, чтобы сформировать общее пространство расстояний между словами и изображениями.
Далее мы разберем сам процесс диффузии — как модели учатся убирать шум и превращать хаос в изображение. Мы увидим, что простая идея о том, что «модель просто убирает шум» не совсем соответствует действительности.
Наконец, давайте объединим CLIP и распространение, чтобы понять, как именно текстовые запросы влияют на создание изображений и видео.
КЛИП
2020 год стал переломным для языкового моделирования. Результаты исследований масштабирования нейронных сетей и появление GPT-3 показали, что «больше» действительно означает «лучше».
Огромные модели ИИ, обученные на гигантских наборах данных, выявили способности, которых просто не существовало в моделях меньшего размера.
Исследователи быстро применили те же идеи к изображениям.
В феврале 2021 года команда OpenAI представила модель CLIP, обучение которой основывалось на 400 миллионах пар «изображение — текстовая подпись», собранных из Интернета.
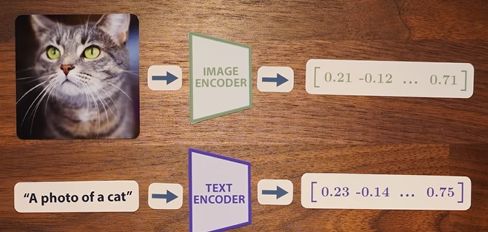
CLIP состоит из двух моделей: одна обрабатывает текст, другая — изображения.
Результатом каждого из них является вектор длиной 512, и основная идея состоит в том, что векторы для одного изображения и его подписи должны быть похожими.
Для этого была разработана контрастная схема обучения.
Например, набор данных может содержать фотографию кошки, собаки и человека с подписями «фото кошки», «фото собаки» и «фото мужчины».
В визуальную модель передаются три изображения, а в текстовую модель — три текста. Мы получаем шесть векторов (числа расстояний с направлением движения) и хотим, чтобы пары, соответствующие друг другу, имели наибольшее сходство (имели наименьшее расстояние).
При этом учитывается не только сходство соответствующих пар, но и различие всех остальных комбинаций.
Мы можем размещать векторы для изображений в виде столбцов матрицы, а для текста — в виде строк.
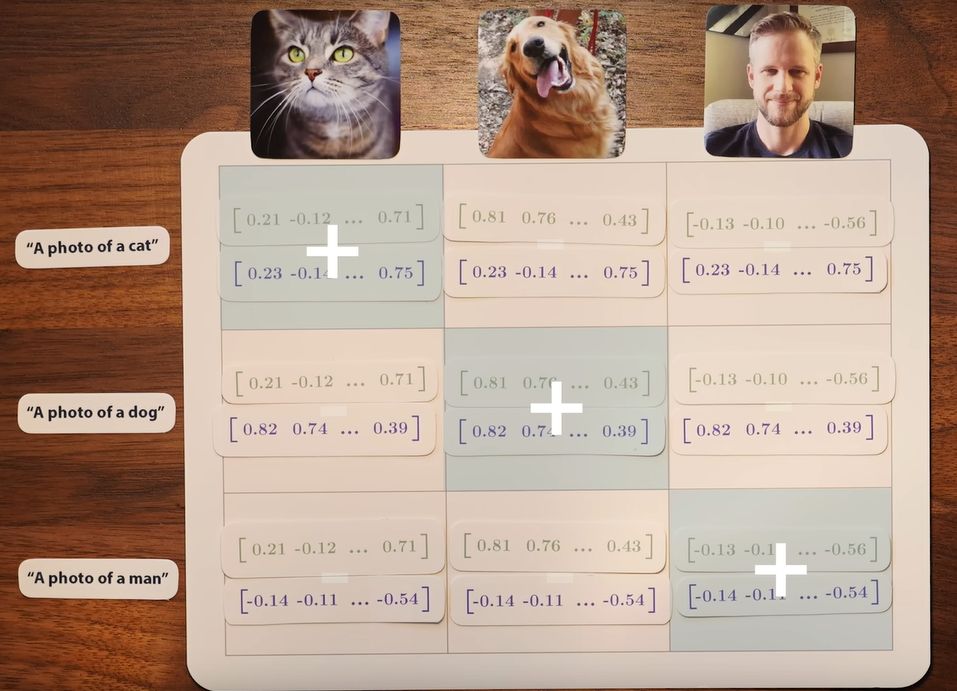
Пары по диагонали — правильные совпадения, а вне ее — неправильные. Цель CLIP — максимизировать сходство правильных пар и минимизировать сходство неправильных.
Это «контрастное» обучение дало модели название: Контрастное предварительное обучение языку и изображению (CLIP).
Сходство измеряется по школьной формуле – косинусу угла между двумя прямыми (векторами). Если угол между векторами равен нулю, их косинус равен 1 – это максимальное сходство.
Итак, CLIP обучен так, что связанные тексты и изображения «смотрят» в одном направлении в общем пространстве.
Учитывая расстояния между определенными объектами, ИИ может давать промежуточные результаты. Например, если взять две фотографии одного и того же человека: в шляпе и без, и посчитать разницу в расстоянии между их векторами, то результат будет соответствовать понятию «шляпа».

То есть, вычитая и добавляя расстояния (векторы), оказывается можно работать с понятиями, а не только с изображениями.
CLIP также может классифицировать изображение: просто сравните его числовое расстояние с набором расстояний для возможных сигнатур и выберите то, которое имеет наибольшее сходство.
Таким образом, CLIP создает мощное пространство, в котором изображения связаны с текстом. Но это работает только в одном направлении: от данных к векторам, а не наоборот.
Диффузионные модели искусственного интеллекта
В том же 2020 году команда из Беркли опубликовала работу Denoising Diffusion Probabilistic Models (DDPM). Он впервые показал, что можно генерировать высококачественные изображения путем пошагового преобразования шума в изображения.
Идея проста: мы берем набор обучающих изображений и добавляем к ним шум до тех пор, пока они не будут полностью уничтожены. Затем мы учим сеть выполнять обратный процесс — удалять шум.
Однако прямая реализация «убираем шум шаг за шагом» не работает. Исследователи из Беркли предложили другую схему: берем «чистое изображение», искажаем его и идем в обратном направлении — от шума к исходному изображению.

Этот подход работает намного лучше, чем поэтапное восстановление.
Немаловажно и то, что во время генерации модель на каждом шаге заново добавляет шум — и это делает результаты более наглядными.
Причина объясняется теорией броуновского движения: добавление случайного шума помогает избежать «слипания» точек в центре распределения данных и воспроизводит их полное разнообразие.
В результате вместо среднестатистического размытого изображения мы получаем множество реалистичных вариантов.
ИИ создает изображения, отсчитывая время назад
Модели диффузии можно интерпретировать как изучение зависящего от времени векторного поля, которое указывает направление перехода от шума к данным.
Представим себе двумерный пример, где каждая точка представляет собой небольшое изображение в два пикселя. Если добавить шум, точка совершает случайные шаги – это броуновское движение.
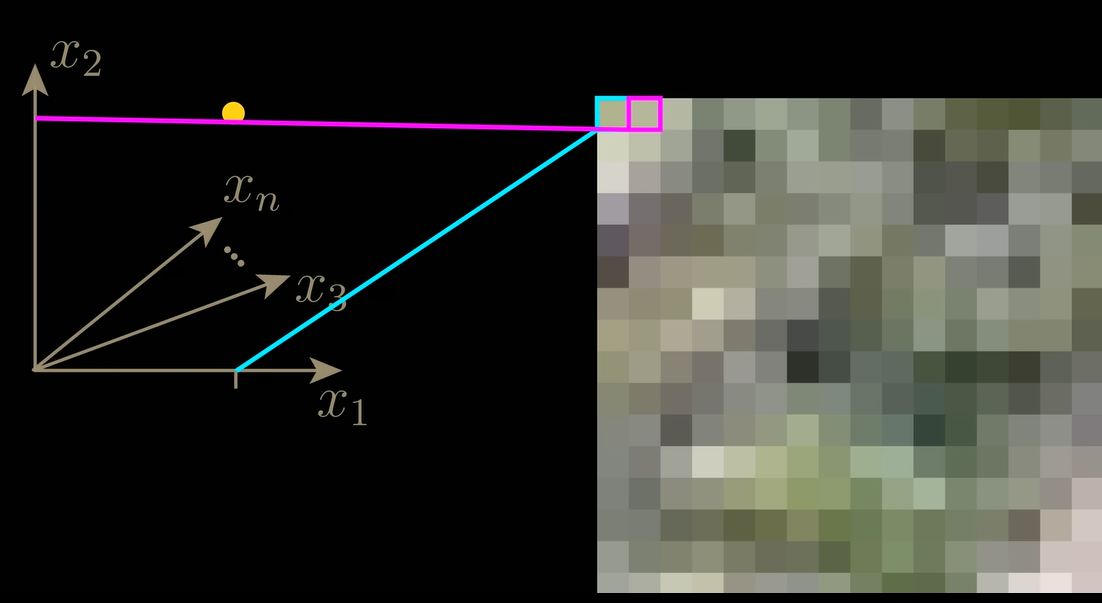
Модель учится «поворачивать время вспять», возвращая точки обратно в исходную структуру (например, спираль).
Если мы обучим ее не только по координатам, но и по времени t (количеству шагов), модель научится вести себя по-разному на разных этапах — сначала грубо, потом более подробно.
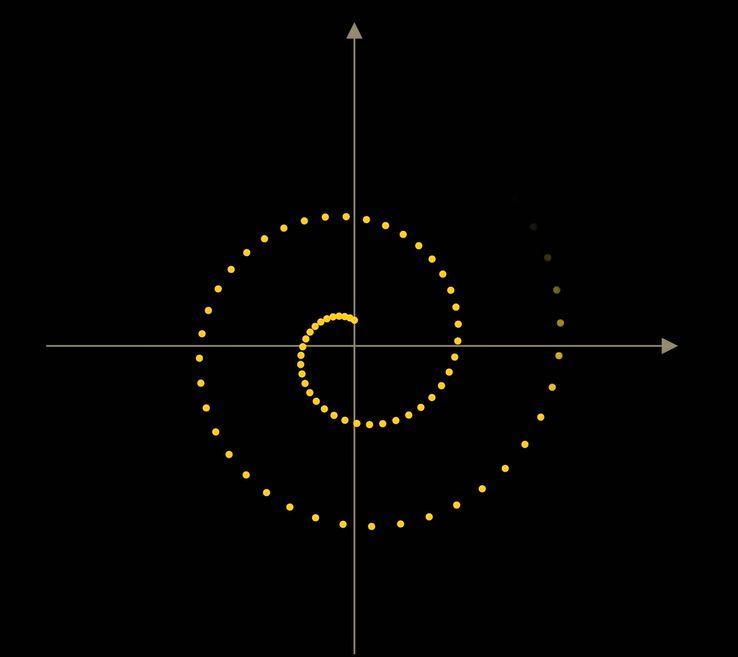
Это делает его гораздо более эффективным.
Из этой модели также следует добавление шума при генерации: оно позволяет сэмплам не «слипаться» в среднее значение, а равномерно заполнять распределение данных.
Если шум не добавлен, модель сходится к центру — то есть создается «усредненное», размытое изображение.

Ничего
Вскоре появился упрощенный метод DDIM (неявные модели шумопонижения и диффузии), который доказал, что то же качество можно получить без случайных шагов.
Он основан на аналитической связи между стохастическим уравнением (с шумом) и обыкновенным детерминированным дифференциальным уравнением без шума.
DDIM позволяет генерировать изображения быстрее и без потери качества.
Оба метода, DDPM и DDIM, приводят к одинаковому распределению результатов, но DDIM делает это детерминированно, без случайности.
В WAN используется дальнейшее развитие этой идеи — метод согласования потоков.
DALL·E 2 и сочетание CLIP с диффузией
К 2021 году стало ясно, что диффузионные модели могут создавать высококачественные изображения, но плохо реагируют на текстовые подсказки.
Идея совмещения CLIP и диффузии показалась естественной: CLIP умеет хорошо сравнивать слова и картинки и может контролировать процесс создания картинок методом диффузии.

В 2022 году команда OpenAI именно это и сделала, создав unCLIP, коммерческая версия которого известна как DALL·E 2.
DALL·E 2 учится преобразовывать векторы из CLIP в изображения, и делает это с невероятной точностью.
Текстовые векторы передаются в диффузионную модель как дополнительное условие, и она использует их для более точного удаления шума согласно описанию.
Этот метод называется кондиционированием.
Но кондиционирование само по себе не гарантирует полного соответствия запросу. Для этого потребуется еще одна хитрость.
Руководство
Вернемся к примеру со спиралью. Если разные части спирали соответствуют разным классам (людям, собакам, кошкам), то обусловленность помогает, но не идеально: точки путаются.
Решением является руководство без классификаторов. Модель преподается как в классе, так и без него.
Во время генерации мы можем сравнивать векторы для условной и безусловной моделей. Разница между ними указывает направление к искомому классу, и мы можем усилить это направление коэффициентом ? (альфа).
В результате модель точнее воспроизводит нужные объекты — например, дерево в пустыне наконец-то появляется и становится все более реалистичным, если увеличить ?.
Этот принцип стал стандартом в современных моделях.
В WAN используется еще более интересная опция — отрицательные подсказки.
То есть пользователь может явно указать, что он не хочет видеть в видео (например, «лишние пальцы» или «движение назад»), и эти факторы вычитаются из результата.
Заключение
С момента публикации DDPM в 2020 году и до сегодняшнего дня разработка диффузионных моделей шла бешеными темпами. Современные системы, способные конвертировать текст в видео, выглядят практически нереально.
Самое впечатляющее, что все эти части — кодеры текста, векторные поля, процессы обратной диффузии — настолько точно скоординированы друг с другом, что образуют целостный механизм. И все это основано на простых математических формулах и геометрии. В результате появились модели, напоминающие машины нового типа.
Теперь вам не нужна камера, художник или аниматор, чтобы создавать реалистичные и красивые изображения или видео. Достаточно всего нескольких слов текста.
Источник: Лаборатории Уэлча.