
Практически каждый сейчас пробует присоединиться к миру искусственного интеллекта. Одним из последних свой искусственный интеллект выпустил производитель процессоров AMD. Языковая модель AMD-135M со спекулятивным декодированием призвана распространить использование искусственного интеллекта.
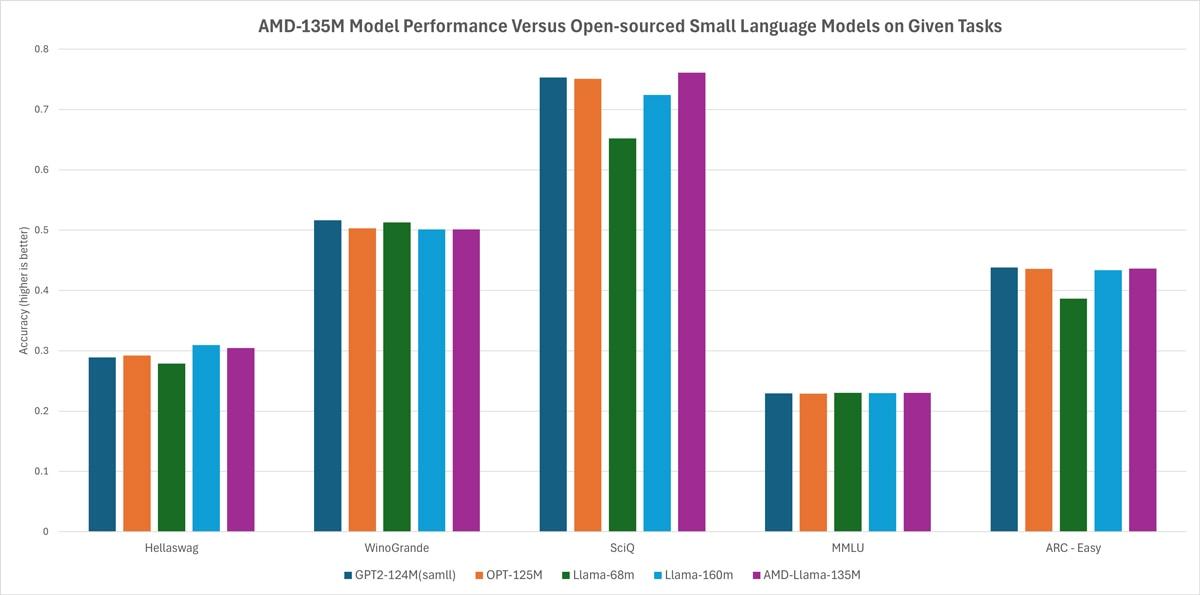
AMD-135M – это первая маленькая языковая модель для семейства Llama, которая была обучена с нуля на ускорителях AMD Instinct MI250 с использованием 670 млрд токенов и разделена на две модели: AMD-Llama-135M и AMD-Llama-135M.
Предыдущая учеба: модель AMD-Llama-135M была обучена с нуля с использованием 670 миллиардов токенов общих данных в течение шести дней с помощью четырех узлов MI250.
Точная настройка кода : Вариант кода AMD-Llama-135M был сконфигурирован с помощью дополнительных 20 миллиардов токенов данных кода, что заняло четыре дня на том же оборудовании.
Учебный код, набор данных и весы для этой модели открыты, чтобы разработчики могли воспроизвести модель и помочь в обучении других искусственных интеллектов.
Большие языковые модели обычно используют авторегрессионный подход для вывода. Однако основным ограничением этого подхода является то, что каждый проход вперед может генерировать только один маркер, что приводит к низкой эффективности доступа к памяти и влияет на общую скорость вывода.
Появление спекулятивного декодирования решило эту проблему. Основной принцип предполагает использование небольшой черновой модели для создания набора токенов-кандидатов, которые затем проверяются большей целевой моделью. Этот подход позволяет каждому прямому проходу генерировать несколько токенов без ущерба для производительности, тем самым значительно уменьшая потребление доступа к памяти и обеспечивая улучшение скорости на несколько порядков.
Обеспечивая эталонную реализацию с открытым исходным кодом, AMD не только расширяет свои возможности искусственного интеллекта, но способствует инновациям в сообществе искусственного интеллекта.