
Чат-бот ChatGPT на основе нейросети GPT-3 наделал шум в СМИ и стал первым в истории приложением, которое набрало 100 млн пользователей за первые два месяца своего существования. Сгенерированные им тексты выглядят так, будто их писал человек и не удивительно, что даже президенты уже читают речи, написанные ChatGPT. Параллельно с этим ChatGPT также пишет программный код и почти устроился на должность программиста с зарплатой $183 000 в год. А еще ChatGPT делают основой для виртуальной подруги. Ответы и возможности ChatGPT могут выглядеть магически, поэтому заглянем под капот этой магии.

Что такое ChatGPT
ChatGPT – это чат-бот, доступный на сайте chat.openai.com. Он может автоматически генерировать текст почти на любую тематику и результат оказывается удивительно замечательным. Текст будет очень похож на тот, что напишет человек на ту же тему.
Для использования ChatGPT требуется действительный телефонный номер, на который придет SMS с кодом подтверждения. При этом украинский телефонный номер пока не подходит, поскольку для нашей страны этот чат-бот официально недоступен. Украинские власти уже просят компанию OpenAI , которая создала этот чат-бот, открыть украинцам доступ к своему продукту.
Используя номер телефона из страны, где официально работает ChatGPT, можно будет свободно им пользоваться в Украине. VPN требуется только при регистрации. Сам сервис ChatGPT доступен бесплатно и без ограничения количества вопросов, которые можно задавать этому чат-боту.
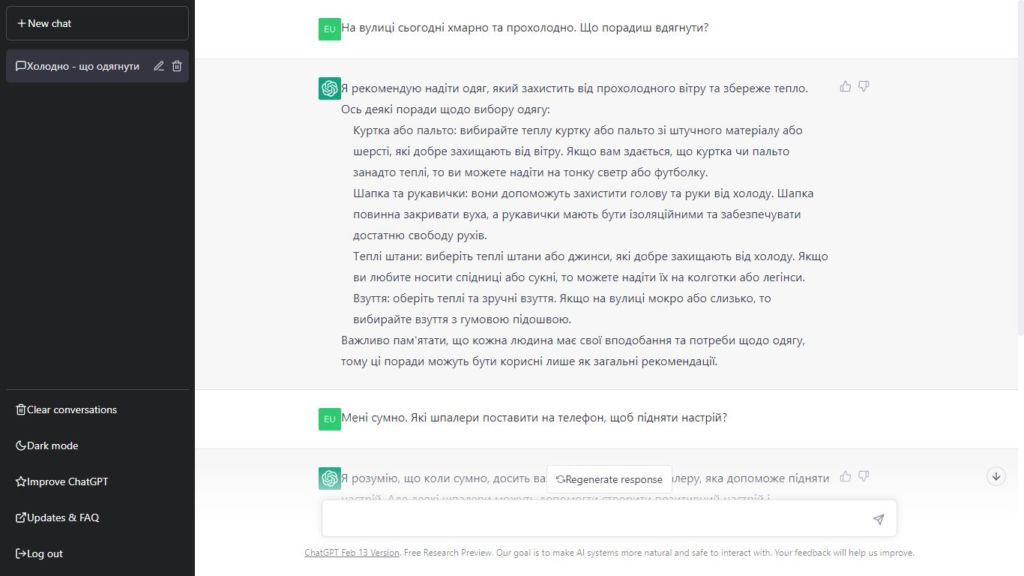
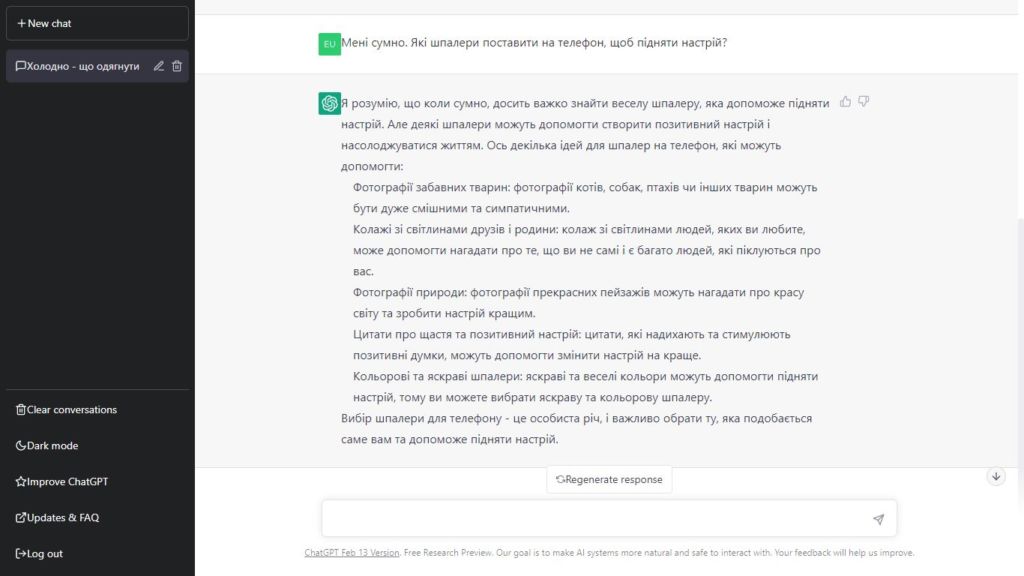
Использование ChatGPT напоминает общение с человеком. Вы в чате оставляете свои просьбы, а чуть ниже чат-бот генерируете свой ответ. Это анимировано так, будто ответ действительно пишется постепенно. Общаться с ChatGPT можно почти на любом языке, включая украинский.
Или попросите ChatGPT писать программный код:
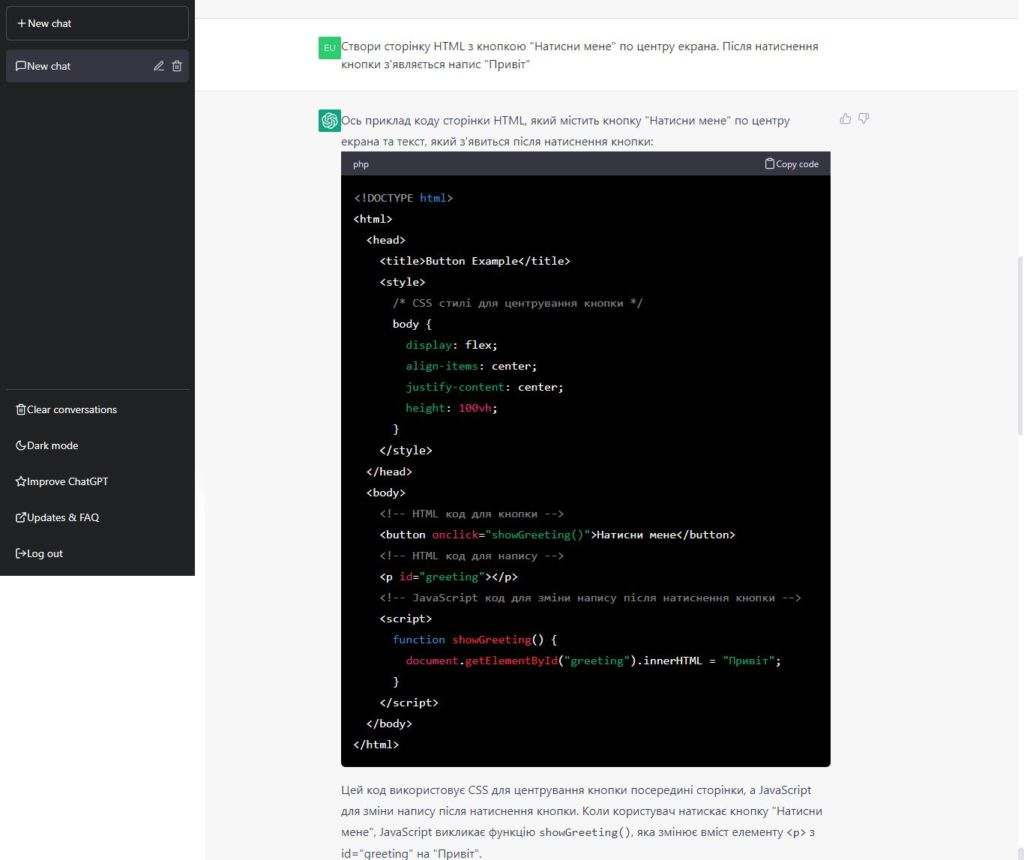 Этот код работает — убедитесь в этом сами, скопировав этот код из скриншота в текстовый файл с расширением HTML и открыв этот файл в своем браузере. Вот ссылка на уже готовый файл.
Этот код работает — убедитесь в этом сами, скопировав этот код из скриншота в текстовый файл с расширением HTML и открыв этот файл в своем браузере. Вот ссылка на уже готовый файл.
Как работает ChatGPT
Современные нейросети способны отвечать настолько человечно и в тему, что у некоторых людей создается впечатление, будто чат-бот имеет сознание. Однако на самом деле никакого понимания темы у чат-ботов нет, а есть статистика и математика.
Первое, что нужно объяснить, это то, что искусственный интеллект (ШИ) ChatGPT всегда пытается сделать это создать «умное продолжение» любого текста, который он имеет на данный момент. Под «умным» мы подразумеваем «то, что можно было бы ожидать, чтобы кто-то написал, увидев, что люди написали на миллиардах веб-страниц».
Итак, допустим, у нас есть текст (Лучше всего в ИИ — это его способность). Представьте себе, что вы сканируете миллиарды написанных людьми страниц (скажем, в интернете и оцифрованных книгах) и находите все экземпляры этого текста. Имея такой массив информации, можно составить список, какое слово следует после этого текста и с какой вероятностью.
ChatGPT эффективно делает нечто подобное, за исключением того, что он не смотрит на буквальный текст; он ищет вещи, которые в определенном смысле «совпадают по значению». Но конечным результатом является то, что он создает ранжированный список слов, которые могут быть следующими вместе с «вероятностями»:

Итак, когда ChatGPT пишет свой ответ, он, по сути, просто спрашивает снова и снова: «Каким должно быть следующее слово, учитывая текущий текст» и каждый раз добавляет слово.
Хорошо, на каждом шагу у чат-бота есть список слов с вероятностью. Но какое из них действительно выбрать, чтобы добавить к ответу, который он пишет? Можно подумать, что это должно быть слово с «высоким рейтингом» (т.е. наиболее часто встречающееся в написанных людьми таких текстах).
Но если просто выбирать слова по процентам вероятности, мы обычно получаем очень «плоское» эссе, которое, кажется, никогда не «проявляет творчества» (и даже иногда повторяет слово в слово). Но если иногда (наугад) мы выберем слова с более низким рейтингом, мы получим «интереснее» эссе.
Тот факт, что здесь случайность, означает, что если мы используем один и тот же запрос несколько раз, мы, вероятно, будем каждый раз получать различные эссе. Существует особый так называемый параметр «температуры», определяющий, как часто будут использоваться слова с более низким рангом, и для создания эссе оказывается, что «температура» 0,8 кажется лучшей.
Почему именно нейросеть может писать как человек
Выбирая следующее слово в предложении по его популярности в речи выходит чушь, необходимо добавить промежуточные шаги, которые будут лучше выбирать слова.
К примеру, в английском языке существует около 40 000 довольно часто употребляемых слов. И, посмотрев на большой массив английского текста (например, несколько миллионов книг с несколькими сотнями миллиардов слов), мы можем получить оценку того, насколько распространено каждое слово. И, используя это, мы можем начать генерировать «предложения», в которых каждое слово выбирается наугад независимо с той же вероятностью, что оно появляется в этом массиве. Вот пример того, что мы получаем:
![]()
Это предложение – полная чушь.
Как алгоритм лучше писать ответ? Он может начать принимать во внимание не только вероятности для отдельных слов, но и вероятности для пар или большего количества слов. Делая это для пар, вот 5 примеров того, что мы получаем, во всех падежах, начиная от слова «кошка»:

Эти предложения уже немного больше похожи на нормальные, хотя в целом они тоже полная чушь.
Если бы мы смогли использовать достаточно длинные n-граммы, мы фактически получили ChatGPT — в том смысле, что мы бы получили что-то, что генерировало бы последовательности слов длиной эссе с правильным написанием.
Но вот проблема: нет даже около текстов достаточной длины на английском языке, чтобы можно было вывести эти вероятности.
В интернете может быть несколько сот миллиардов слов; в книгах, оцифрованных, может быть еще сто миллиардов слов. Но из 40 000 обычных слов даже количество возможных 2-граммов уже составляет 1,6 миллиарда, а количество возможных 3-граммов составляет 60 триллионов. Поэтому мы не можем оценить вероятности даже для всего этого текста, который есть там. И когда мы дойдем до «фрагментов эссе» из 20 слов, количество возможностей будет больше, чем количество частиц во Вселенной, поэтому в определенном смысле их никогда нельзя будет записать.
Какое решение? Общая идея состоит в том, чтобы создать языковую модель, которая позволит нам оценить вероятность появления последовательностей, даже если у нас никогда не было таких последовательностей в написанных людьми текстах. В основе ChatGPT лежит именно так называемая «большая языковая модель» (LLM), которая была создана для качественной оценки этих вероятностей.
Что такое модель
Скажем, вы хотите знать (как это сделал Галилей в конце 1500-х годов), сколько времени понадобится пушечному ядру, сброшенному с каждого этажа Пизанской башни, чтобы удариться о землю.
Ну вы можете просто измерить это в каждом случае и составить таблицу результатов. Или вы могли бы сделать то, что есть сущность теоретической науки: создать модель, которая дает определенную процедуру для вычисления ответа даже в случаях, не измеряемых во время практического эксперимента.
Представим, что у нас есть (несколько идеализированные) данные о том, сколько времени нужно пушечному ядру, чтобы упасть с разных этажей:
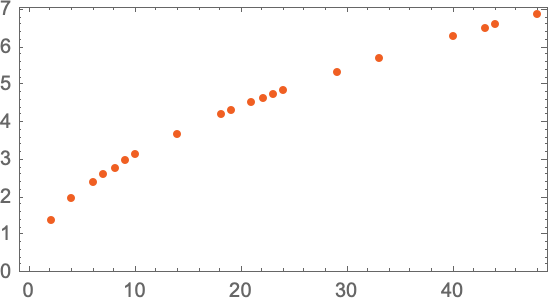
Как мы выясним, сколько времени понадобится, чтобы упасть с этажа, на котором мы не производили измерения? Если мы не знаем, какой физический закон управляет падением ядра и все, что у нас есть – это ограниченные данные измерений, мы можем сделать математическое предположение, например, что, возможно, нам следует использовать прямую линию как модель:
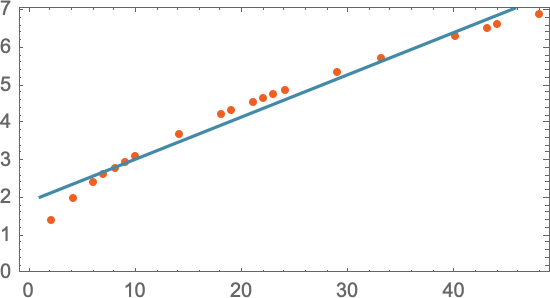
Мы могли бы выбрать разные прямые линии. Но прямая линия в этом случае – то, что в среднем ближе всего к имеющимся данным. Имея эту прямую линию, мы можем оценить время падения с любого этажа.
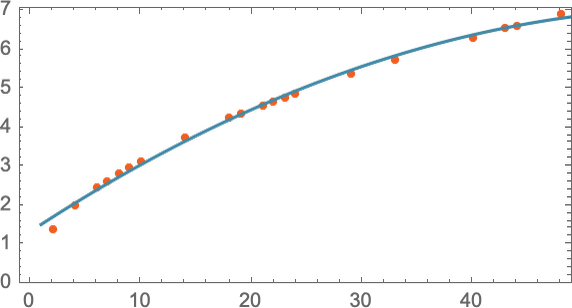
Откуда мы знаем, что нужно использовать прямую линию? Просто ее уравнение легко для вычисления. Однако никто не мешает попробовать что-то математически сложнее, скажем, a+bx+cx2 — и тогда в этом случае модель станет точнее:
Но и слишком усложнять тоже не стоит, потому что результаты модели могут оказаться далекими от экспериментальных данных. Например, уравнение a + b/x + c sin(x), очевидно, совсем не подходит на роль модели падения пушечного ядра с определенного этажа:
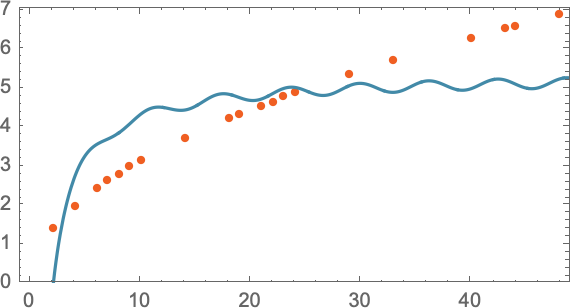
Следует понимать, что любая модель имеет определенную базовую структуру, а затем определенный набор параметров для более точной настройки, чтобы она лучше соответствовала экспериментально полученным данным.
В случае с ChatGPT используется много таких параметров – около 175 миллиардов.
Почему именно нейросети
Для решения человекоподобных задач (распознавание изображений или текста, генерация изображений или текста) наиболее популярный и успешный текущий подход использует нейронные сети. Изобретенные — в форме, чрезвычайно близкой к их использованию сегодня — в 1940-х годах. -biznesom-130693.html»>нейронные сети можно рассматривать как простые идеализации того, как работает мозг.
В человеческом мозге имеется около 100 миллиардов нейронов (нервных клеток), каждый из которых способен производить электрический импульс несколько десятков раз в секунду. Нейроны соединены в сложную сеть, посылая свой сигнал другому.
В грубом приближении определенный нейрон отправляет свой электрический импульс другому нейрону, если получит определенный набор импульсов от тех, с кем он связан. Эти связи не равнозначны и некоторые из них важнее других. Числовое выражение такой важности связи между нейронами называется «вес».
Вот приближенное описание того, как человек распознает изображение. Когда мы «видим изображение», происходит то, что фотоны света от изображения падают на клетки сетчатки, которые производят электрические сигналы и посылают их в нервные клетки дальше (зрительный нерв). Нервные клетки зрительного нерва соединены с другими нервными клетками в мозге. В конце концов сигналы проходят через целую последовательность слоев нейронов, пошагово распознавая элементы изображения (цвет, горизонтальные и вертикальные линии, размер и т.п.). Именно в этом процессе мы «узнаем» изображение как объект, формируя мнение, что мы видим что-нибудь.
Хорошо, но как такая нейронная сеть распознает вещи? Ключевым является понятие аттракторов. Представьте, что у нас есть рукописные изображения цифр 1 и 2:

Мы почему-то хотим, чтобы все 1 «привлекались в одно место», а все 2 «привлекались в другое место». Или, другими словами, если изображение каким-то образом «ближе к 1», чем к 2, мы хотим, чтобы оно оказалось на месте единицы и наоборот.
Мы можем рассматривать это как реализацию своего рода «задачи распознавания», в которой мы не делаем идентификации того, на какую цифру определенное изображение «наиболее похоже», а скорее мы просто видим, к какой точке больше тянется (атрактируется) изображение.
Итак, как заставить нейронную сеть «выполнять задачи распознавания»? Рассмотрим этот очень простой случай:
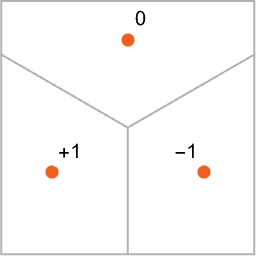
Наша цель состоит в том, чтобы взять «вход», соответствующий положению {x,y}, а затем «распознать» его как любую из трех точек, к которой он ближе всего. Или, другими словами, мы хотим, чтобы нейронная сеть вычислила функцию {x,y}.
Итак, как это сделать с помощью нейронной сети? В конце концов нейронная сеть — это связанная коллекция идеализированных «нейронов», обычно расположенных слоями, простым примером которых являются:
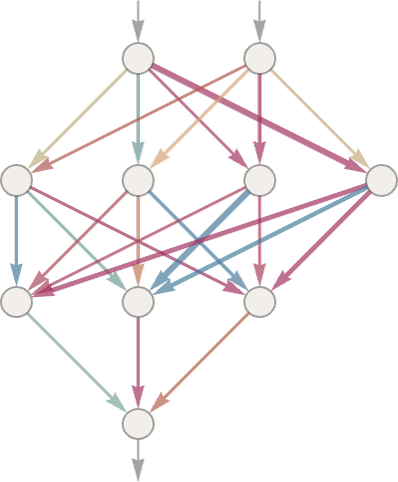
Каждый «нейрон» эффективно настроен для вычисления простой числовой функции. А чтобы использовать сеть, мы просто подаем числа (например, наши координаты x и y) в верхней части, затем заставляем нейроны на каждом слое оценивать свои функции и передаем результаты через сеть, производя конечный результат.
В традиционной (биологически подобной) установке каждый нейрон фактически имеет определенный набор входящих соединений от нейронов на прежнем уровне, причем каждому соединению присваивается определенный «вес» (который может быть положительным или отрицательным числом). Значение данного нейрона определяется умножением значений «предыдущих нейронов» на их соответствующий вес, а затем их добавлением и умножением на константу и, наконец, применением «пороговой» (или «активационной») функции. С математической точки зрения, если нейрон имеет входы x = {x1, x2…}, тогда мы вычисляем f[w. x + b], где весы w и константа b обычно выбираются по-разному для каждого нейрона в сети; функция f обычно одинакова.
Нейронная сеть ChatGPT также соответствует подобной математической функции, но фактически с миллиардами параметров.
С простой «задачей на распознавание» легко понятно, что такое «правильный ответ». Но в проблеме распознавания рукописных цифр все не столь однозначно. Что, если бы кто-нибудь написал «2» так плохо, что это выглядело как «7»? Или что, если нейросети показать фотографию с собакой в ??костюме кота?
Можем ли мы сказать «математически», как сеть определяет отличия между распознанными объектами? Не совсем. Она просто делает то, что делает нейронная сеть. Но оказывается, что обычно это достаточно хорошо согласуется с тем, как подобные нечеткие объекты распознают люди.
Но мы можем сказать, что нейронная сеть «выбирает определенные черты» (возможно, острые уши среди них) и использует их, чтобы определить, из чего состоит изображение. Но делает ли она это объектно, например, узнает ли кота на изображении по параметру «острые уши»? В основном нет.
Использует ли наш человеческий мозг параметр «острые уши», чтобы узнать кота на изображении? Мы не знаем.
Но примечательно, что первые несколько слоев компьютерной нейронной сети, выделяют аспекты изображений (например края объектов), и примерно так же происходит начальная обработка изображения в человеческом мозге.
Машинное обучение и обучение нейронным сетям
До сих пор мы говорили о нейронных сетях, которые уже знают, как выполнять определенные задачи. Но то, что делает нейронные сети столь полезными в решении практических задач – это их способность учиться на примерах для повышения результатов своей работы.
Когда мы создаем нейронную сеть, чтобы отличать кошек от собак, не нужно писать программу, которая явно находит усы. Мы просто показываем много примеров того, что такое кошка, а что собака, а потом заставляем сеть их различать – это машинное обучение.
Ученая сеть «обобщает» свои навыки распознавания на конкретных примерах, которые она получает. Сеть не просто распознает отдельный пиксельный узор примера изображения кота, который ей был показан. Нейронной сети удается различать изображения на основе того, что мы считаем определенной «общей кошачьей».
Итак, как работает обучение нейронной сети? Это попытка найти весовой коэффициент каждого нейрона, чтобы в итоге нейросеть выдавала желаемый результат.
Как найти весы, которые позволят нейросетям выдавать желаемый результат? Основная идея состоит в том, чтобы дать много примеров «сигнал — результат», на которых сеть «учится», а затем попытаться найти весы, воспроизводящие эти примеры.
Это скучная и тяжелая работа, которой занимаются малооплачиваемые работники. , например, из Кении. ChatGPT также учили сотрудники из Кении, которым OpenAI платила менее $2 в час. Кенийцы, готовившие тренировочные данные для ChatGPT, в интервью Time упоминают, что это была пытка.
Чему нас учит ChatGPT: язык не сложный, хотя люди считают иначе
Человеческий мозг считают удивительным, поскольку с его сетью из «только» 100 миллиардов нейронов (и, возможно, 100 триллионов соединений) ему удается решать достаточно сложные задачи. Существовали даже версии, что в мозгу есть нечто большее, чем его сети нейронов – некий новый слой неоткрытой физики.
В прошлом было много задач, включая написание текстов, которые мы считали «слишком сложными» для компьютеров. А теперь, когда мы видим, как это делает ChatGPT, появляется удивительное заключение. Задачи, например написание эссе, которые мы, люди, можем выполнять и считали их сложными для компьютеров, на самом деле в некотором смысле вычислительно легче, чем мы думали.
Будь у вас достаточно большая нейронная сеть, она могла бы делать все, что легко может сделать человек. Магия ChatGPT в том, что это ограниченная нейросеть (даже несмотря на то, что в ней 175 млрд. весовых коэффициентов). Но, несмотря на это, эта нейросеть, кажется, хорошо работает.
Итак, как ChatGPT с такими ограниченными ресурсами удается генерировать столь человекообразный текст? Возможно, причина в том, что язык на фундаментальном уровне несколько проще, чем кажется. А это значит, что ChatGPT — даже с его чрезвычайно простой структурой нейронной сети — успешно способен «уловить суть» человеческого языка и стоящего за ним мышления. Более того, во время обучения ChatGPT каким-то образом «неявно обнаружил» какие-то закономерности в языке и мышлении, которые делают это возможным.
Успех ChatGPT, возможно, дает нам доказательства фундаментальной и важной части науки: мы можем ожидать, что появятся большие новые «законы языка» – и, в сущности, «законы мышления» – которые можно открыть. В ChatGPT, созданном как нейронная сеть, эти законы в лучшем случае неявны. Но если мы сможем сделать законы четкими, мы сможем делать вещи, которые делает ChatGPT, гораздо более прямыми, эффективными и прозрачными способами.
ChatGPT не имеет явных знаний о правилах речи. Но каким-то образом при обучении эта нейросеть смогла их усвоить и эффективно использовать. Как это случилось? На уровне «общей картины» это непонятно.
Есть ли общий способ определить, что предложение имеет смысл? Для этого нет традиционной общей теории. Но можно считать, что ChatGPT неявно «разработал теорию» после обучения с миллиардами (вероятно, значимых) предложений по интернету и книгам.
Пока это лишь предположение, однако успех ChatGPT неявно раскрывает важный факт, что на самом деле существует гораздо больше структуры и простоты в значимом человеческом языке, чем мы когда-либо представляли. В конце концов, могут существовать даже довольно простые правила, которые опишут, как делать текст содержательным с помощью алгоритма.
По материалам: writings.stephenwolfram.com