
Один из самых популярных способов воспроизведения музыки – случайный выбор очередного трека. Казалось бы, в этом нет никакой проблемы – уже давно написаны такие генераторы случайных чисел, максимально возможные без использования специальных аппаратных генераторов рандома. Но известный музыкальный стриминговый сервис Spotify столкнулся с жалобами пользователей. Пользователи хотели рандом, но не настоящим рандом, а более приятным рандом.

Пользователи Spotify спрашивали: «Почему ваша тасовка не случайна?». В сервисе удивлялись, ведь треки в плейлистах воспроизводились в случайном порядке.
Так кто был прав? Как оказалось, и Spotify, и пользователи были правы, но все немного сложнее.
Как было случайное воспроизведение треков в Spotify
С момента запуска службы Spotify использовалось перемешивание Фишера-Йейтса, чтобы создать идеально случайную перетасовку списка воспроизведения.
Однако совершенно случайный означает, что последующие события никак не связаны с предыдущими.
При поистине случайном воспроизведении вполне возможно, что пользователю придется прослушать треки альбома последовательно один за другим. Конечно, вероятность этого очень низкая. Зато обыденным делом является воспроизведение двух или трех песен одного автора.
Ошибка игрока
Сначала в Spotify не понимали, что пользователи пытались сказать, говоря, что случайное воспроизведение треков не случайно. Но потом инженеры сервиса внимательнее прочли комментарии и заметили, что некоторые люди не хотят, чтобы один и тот же артист играл два или три раза в течение короткого периода времени.
Понятно, что мы, люди, время от времени плохо оцениваем возможность. Предположим, что вы каждый день на работе подбрасываете монету, чтобы решить, где обедать. Первые четыре дня недели монета решила, что вам стоит есть тайскую еду, а вы предпочитаете индийскую. Вы можете подумать: «На этой неделе монета четырежды решалась в пользу тайской, сегодня она должна быть индийской».
Если вы думаете, что монета имеет большую вероятность принять решение за индейцев в пятницу, вы ошибаетесь. Бросить монету в миллионный раз – все равно, что бросить ее впервые Обычная монета не имеет памяти, не знает, кто ее бросил и т.д. Итак, и орел, и решка имеют одинаковую вероятность выпасть в пятницу – 50% [примечание переводчика: недавнее исследование с подбрасыванием монетки более 300 тыс. раз показало, что монетка не падает совершенно случайно. Она чаще оказывается на той стороне, с которой ее бросали].
Другой пример: люди часто думают, что если они не выиграли ничего в лотерею со скретч-картами несколько раз подряд, у них должно быть больше шансов выиграть сейчас. Это явление называется ошибкой игрока, и это та же ошибка, которая привела к ошибке относительно тайской/индийской кухни.
Пользователи Spotify стали жертвами ошибки игрока. Если вы только что услышали песню от определенного исполнителя, то это не значит, что следующая песня, скорее всего, будет от другого исполнителя в совершенно случайном порядке.
Пользователь всегда прав и Spotify редактирует случайность
Однако старая поговорка говорит, что пользователь всегда прав, поэтому в Spotify решили найти способы изменить наш алгоритм случайной тасовки треков, чтобы пользователи были более счастливы. В Spotify узнали, что пользователи не любят абсолютной случайности.
Казалось, что это проблема, которую должен был решить кто-то другой раньше. Действительно, нашлась публикация в блоге «Искусство тасовки музыки» Мартина Фидлера, которая решает ту же проблему.
Однако его алгоритм сложен и может быть очень медленным в некоторых случаях, поэтому программисты Spotify изменили его, чтобы лучше отвечать потребностям сервиса.
Основная идея очень похожа на методы, используемые в дизеринге. Предположим, у нас есть черно-белое изображение, использующее несколько сотен оттенков серого.

Мы хотели бы еще больше упростить изображение, используя только пиксели двух цветов, черный и белый. Мы могли бы использовать случайную выборку: скажем, пиксель имеет 80% оттенка серого, тогда у него будет 80% шансов стать черным и 20% шансов стать белым. Мы обрабатываем пиксели один за другим и для каждого случайным образом определяем новый цвет на основе исходного оттенка серого. Однако результат очень далек от удовлетворительного.
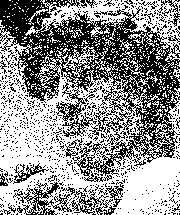
Как видите, черные пиксели образуют кластеры, а также большие белые пятна. Было бы лучше, если бы черные и белые пятна были распределены более равномерно. Другие алгоритмы, такие как дизеринг Флойда-Штейнберга, избегают кластеров и дают гораздо лучшие результаты. Почти полностью исчезли кластеры, которые мы видели на предыдущем снимке.

Мы можем черпать вдохновение из алгоритмов сглаживания, чтобы решить нашу проблему с кластерами песен одного исполнителя, попытавшись распространить их по всему плейлисту.
Предположим, у нас есть список воспроизведения, содержащий несколько песен The White Stripes, The xx, Bonobo, Britney Spears (Toxic!) и Jaga Jazzist. Для каждого артиста мы берем его песни и стараемся максимально равномерно растянуть их по всему плейлисту. Затем мы собираем все песни и упорядочиваем их по позиции.
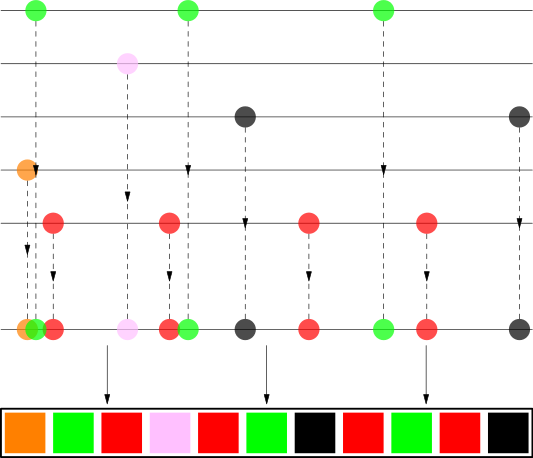
Как видите, песни от исполнителя хорошо распределены, и это выглядит достаточно случайно для человеческого глаза.
Рассмотрим подробнее, как работает алгоритм.
- Предположим, у нас есть 4 песни от The White Stripes, как на рисунке выше. Это означает, что они появляются примерно через каждые 25% длины списка воспроизведения. Мы раскладываем 4 песни вдоль строки, но их расстояние будет меняться случайным образом от примерно 20% до 30%, чтобы окончательный порядок выглядел более случайным. Вы должны видеть, что расстояние между красными кругами на линии неодинаково.
- Мы вводим случайное смещение в начале; иначе все первые песни оказались бы на позиции 0. Вы видите, что и Бритни Спирс, и Джага Джазист имеют одну песню, но случайное смещение приводит к тому, что они появляются в случайном месте списка воспроизведения.
- Песни одного исполнителя Мы также перемешиваем между собой. Здесь мы можем использовать перемешивание Фишера-Йетса или применить тот же алгоритм рекурсивно, например, мы можем предотвратить воспроизведение песен из одного альбома слишком близко друг к другу.
В общем, алгоритм очень прост и его можно реализовать всего за пару строчек программного кода. Он тоже очень быстр и дает достойные результаты.
По материалам: Spotify