
Останнє десятиліття ознаменувалося значним поліпшенням можливостей комп’ютерів сприймати світ навколо. Програмне забезпечення здатне швидко розпізнавати обличчя людей, заміняти людей на фото та відео, підроблювати голоси в аудіо. Смартфони можуть слугувати перекладачами реального часу та редагувати фото «на льоту», а автомобілі навчилися їздити без водія. Роботи розносять їжу, виступають у парламенті та погрожують знищити людство. Такі можливості стали реальністю завдяки технології під назвою глибоке навчання. В її основі – нейронні мережі, і ось як вони працюють.

Швидко про комп’ютерні нейромережі
Комп’ютерні нейромережі – це така структура даних, яка нагадує структуру нейромережі біологічної істоти. Штучні нейромережі також організовані в шари, вихід одного шару під’єднано до входу наступного шару.

Науковці почали експериментувати зі штучними нейромережами ще в 1950-х роках. Стати такими, як ми їх знаємо сьогодні, нейромережі змогли завдяки двом великим проривам у 1986 році та 2012 році. Останній став революцією глибокого навчання, який переніс результати роботи нейромереж на якісно новий рівень. Цей прорив став можливим завдяки зростанню обсягів даних та обчислювальної потужності комп’ютерів.
Нейромережі в 1950-х
У 1957 році науковець Університету Корнелла Френк Розенблатт опублікував статтю з описом нейромережі, які він назвав перцептроном. У 1958 році з допомогою ВМС США він побудував робочий прототип, який аналізував зображення розміром 20х20 пікселів та розпізнавав прості геометричні форми.
Підписуйтесь на наш канал у Telegram: https://t.me/techtodayua
«ВМС сьогодні відкрило зародиш електронного комп’ютера, який зможе ходити, бачити, говорити, писати, відтворювати себе та бути свідомим щодо свого існування», – писав тоді журналіст The New York Times.
Фундаментально кожен нейрон – лише математична функція. Він обраховує загальну вагу сигналів на своєму вході, яка слугує основою для розрахунку нелінійної функції, що називається функцією активації.
Особливість перцептрона Розенблатта – у можливості «вчитися» на прикладах. Нейромережу тренують коригувати обрахунок ваги сигналів на вході на заданих прикладах. Якщо нейромережа правильно розпізнає заданий образ – вагу збільшують. Якщо розпізнавання неправильне – вагу зменшують.
У 1960-х перспективи нейромереж здавалися райдужними, але науковці Марвін Мінскі та Сеймур Паперт у своїй книзі 1969 року показали, що ранні нейромережі мали суттєві обмеження. Ті нейромережі мали один-два шари, і Мінскі та Паперт показали, що вони не здатні моделювати складні явища реального світу.
Стало очевидно, що потрібно розвивати глибокі нейромережі із значно більшою кількістю шарів. Однак на заваді стали обмежені обчислювальні можливості комп’ютерів того часу. Також ще не винайшли простий алгоритм для тренування глибоких нейромереж.
У період 1970-х та ранніх 1980-х нейромережі вже не сприймалися як проривні. Поки в 1986 році не опублікували статтю з описом практичного методу тренування глибоких нейромереж – методу зворотного розповсюдження похибки.
Уявіть, що ви програміст, якому потрібно створити програму, що розпізнає наявність хот-дога на фотографії. Ви запускаєте нейромережу, яка на вході отримує зображення, а на виході видає результат 0 (відсутність хот-дога на фото) та 1 (наявність хот-дога на фото).
Для тренування нейромережі ви збираєте тисячі фотографій і проставляєте на них мітку наявності хот-дога. Перше із цих фото направляється на вхід нейромережі. Наприклад, на ньому є хот-дог, але нейромережа видала значення 0,07. Це майже 0, що означає відсутність хот-догу. Це неправильна відповідь – нейромережа повинна була видати значення близьке до 1.
За алгоритмом 1960-х років ваги на вході в нейромережу коригуються так, щоб при повторному аналізу цієї картинки нейромережа видавала правильну відповідь. Це було легко зробити вручну, якщо нейромережа мала один-два шари. При значному збільшенні шарів з’являлося надто багато змінних.
За методом зворотного розповсюдження похибки алгоритм сам обраховував невелику зміну у вхідних вагах кожного шару нейромережі так, щоб отримати максимального наближений до правильного результат. Це дає таблицю похибок на кожному шарі нейромережі, за якою можна коригувати ваги нейронів. Алгоритм повторюється знову і знову, коригуючи вхідні ваги нейронів.
Метод зворотного розповсюдження похибки дозволив створювати нейромережі з десятками та сотнями шарів. При цьому нейромережі могли мати складну внутрішню структуру.
Цей метод відкрив другу хвилю розвитку нейромереж і їхнє практичне використання. У 1998 дослідники AT&T показали, як використовувати нейромережі для розпізнавання рукописних цифр та автоматичної обробки паперових чеків.
У ті роки нейромережі все ще залишалися однією з альтернатив. Студентам викладали також вісім інших можливих алгоритмів машинного навчання.
Великі дані показали можливості нейромереж
Метод зворотного розповсюдження похибки дозволив ефективно тренувати масштабні нейромережі, але залишалося питання обчислювальної потужності комп’ютерів. У 2012 році Алекс Кріжевскі описав нейромережу AlexNet, показавши, що можна отримати прорив продуктивності, якщо мати величезні масиви даних. AlexNet мала 8 шарів, 650 000 нейронів, 60 млн параметрів.
Нейромережу AlexNet створили три науковці Університету Торонто в рамках академічного конкурсу ImageNet. Для нього організатори «обчистили інтернет», зібравши 1 млн фотографій. Ці знімки були промарковані категоріями відповідно зображеного – вишня, корабель, леопард тощо.
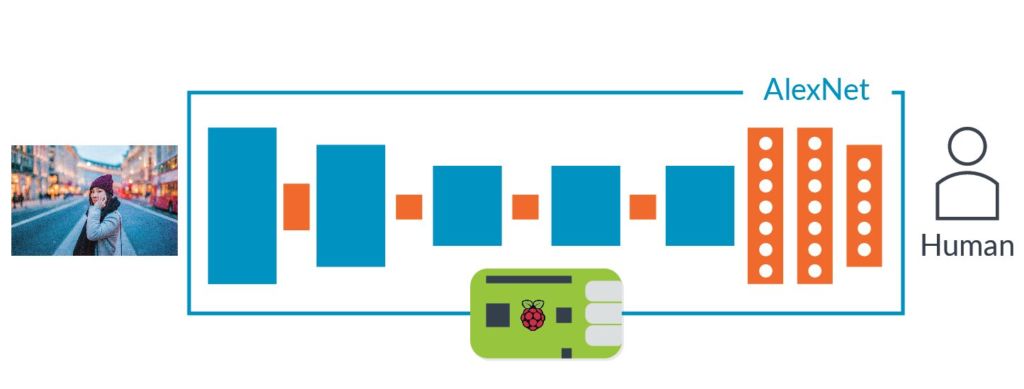
Завданням конкурсу було створити нейромережу, яка могла правильно класифікувати картинки, що їй раніше не зустрічалися. До 2012 року найкращий результат був 25% похибок. Однак AlexNet показав 16% похибок. Найближчий суперник мав 26% похибок.
Автори AlexNet залучили кілька технологій, однією з яких було використання згорткових нейромереж. Останні ефективно тренують невеликі нейромережі, які на вхід отримують зображення не більше 7-11 пікселів на кожен бік і шукають їх по всьому великому знімку.
Іншим досягненням AlexNet було використання відеокарт для тренування. Відеокарти добре пристосовані для одночасного виконання багатьох однакових дій. Саме таким є процес тренування нейромережі.
AlexNet також допоміг величезний набір підготованих для конкурсу ImageNet фотографій. Маючи мільйон знімків, автори нейромережі змогли точно налаштувати 60 млн параметрів нейромережі.
Усі три елементи успіху AlexNet існували задовго до появи цієї нейромережі. Але саме в AlexNet їх використали одночасно, що дозволило нейромережі показати найкращу ефективність.
Бум глибокого навчання
Успіх AlexNet не залишився непоміченим, і глибоке навчання почало витісняти інші алгоритми. Нейромережі швидко ставали ефективнішими: з 16% похибок у 2012 році вони поліпшилися до 2,3% похибок у 2017 році.
Почалася комерціалізації технології глибокого навчання. У 2013 році Google викупив стартап, який заснували автори AlexNet. Та нейромережа і її рішення стали основою для пошуку за картинками в Google Картинки. У 2014 році Facebook почала експериментувати з технологіями розпізнавання облич. З 2016 року Apple використовує глибоке навчання для цієї ж мети у додатках iOS. Голосові помічники Apple Siri, Amazon Alexa, Microsoft Cortana, Google Assistant також базуються на глибокому навчанні.
Для пришвидшення роботи нейромереж компанії також почали розробляти спеціалізовані чипи. Google у 2016 році створив процесор Tensor Processing Unit. Того ж року Nvidia оголосила про архітектуру Tesla P100 з оптимізацією для нейромереж. У 2017 році Intel випустила власний чип зі штучним інтелектом, а у 2018-му такий же створила Amazon. Microsoft нині працює над таким чипом.
Глибокі нейромережі здатні розпізнавати широкий набір складних об’єктів без детальних інструкцій від людини. Найближчими роками очікується подальше розширення їхніх можливостей.
За матеріалами: Arstechnica